
When to repeat yourself
When duplicated code is the better tradeoff.

Hi Friends,
Welcome to the 180th issue of the Polymathic Engineer newsletter.
In a recent article, we talked about the DRY principle and why removing duplication can lead to fewer bugs and more reusable code. As you know, DRY is one of the most well-known rules in software engineering, and most of us learn it early in our careers.
But here’s the thing: DRY is not free. Every time we remove duplication, we pay for it somewhere else. Sometimes it is the coordination between teams. Sometimes it is the tight coupling between components. Sometimes a new business requirement arrives, our common abstraction is not flexible enough to support it and starts to push back.
In a small codebase owned by a single team, this cost is small, and DRY almost always wins. In distributed systems with many services and many teams, the cost can become larger than the duplication it is trying to remove.
There is also a second question that engineers tend to skip. Two sections of code that appear the same may not mean the same thing. Sometimes what looks like duplication is just two things that look alike today and may evolve differently tomorrow,
In this issue, we will see when keeping duplication is a reasonable tradeoff, and when it is worth the effort to remove it. The outline is as follows:
The coordination tax
Is it really duplication?
Sharing code across services: from library to microservice
The same tradeoff inside a codebase
Closing thoughts
Quantify and Eliminate the “Friction Tax” on Your Codebase
Technical debt isn’t just an abstract problem. As AI accelerates code generation, it also compounds debt, acting as a silent tax on your engineering velocity and exponentially increasing developer cognitive load.
SonarQube gives tech leaders and architects the exact visibility they need to stop software entropy in its tracks. By analyzing your codebase against thousands of language-specific rules, SonarQube acts as an automated, multi-layered guardrail that keeps your code predictable, adaptable, and architecturally sound.
Discover how to systematically measure and manage code-level debt with SonarQube.

Thanks to the SonarQube Team for collaborating with me on this article.
The coordination tax
To see why duplication is sometimes the better tradeoff, let’s suppose that two teams are building two services that need a similar piece of functionality. Team A writes its version in its own service, and Team B does the same. The two sections of code look almost identical, but they are in different repos and are owned by different teams.
This is the classic scenario where most engineers reach for DRY and say: it should be a shared component. On the surface, that sounds right. Two teams writing the same thing twice is exactly what DRY warns us about.
However, there is a hidden benefit to leaving the duplication in place. Both teams can move at full speed. There are no meetings to align on the design, no shared roadmap, no review process across team boundaries, and no merge conflicts on someone else’s repository. Each team owns its copy and can change it whenever it wants.
The parts of a project that need everybody in the room don’t get faster when you add more people. They slow down. The cost of sharing is in the meetings, design reviews, sign-offs, and merge negotiations. When you remove duplication by adding a shared component, you also introduce coordination among everyone who uses it.
Of course, the other side of the coin is real too. When each team owns its own copy, a bug fixed in one area doesn’t make it to the other. Knowledge doesn’t spread. The two implementations slowly drift apart, and after a few months, they may not even behave the same way for the same input. This is particularly risky for security-sensitive code because the likelihood of two independent teams getting authentication or encryption right twice is quite low.
So the question is not if we should remove duplication, but what is more expensive in our situation. Which one creates more trouble: the coordination cost of sharing, or the drift cost of duplicating? The answer is different for each team and depends on how often the code changes and how different the two versions are going to be.
Is it really duplication?
Before we think about how to share code, there is another crucial question to answer first: is what we are looking at really duplication?
The fact that two sections of code look very similar does not mean they solve the same problem. Two validation functions that both check “value greater than zero” can look the same on the screen, but they might have different purposes. For example, the first might be validating the user’s age and the second a product price. The validation rules are the same now, but they may evolve differently tomorrow.
This is what we call incidental duplication. It is code that looks the same but does not encode the same knowledge. It is different from inherent duplication, where the same business rule is represented in multiple places. Inherent duplication is something we usually want to remove. Incidental duplication is something we usually want to leave alone.
The tricky thing is that it can be hard to distinguish the two scenarios, especially early in a project. What appears to be duplicated code today could turn out to belong to two different domains tomorrow. Here are some hints to help:
The two call sites are owed by different teams or driven by different stakeholders
The reason for the logic is different on each side, even though the code looks identical
You can imagine a future where one side changes and the other does not
When any of these signals are present, it is usually better to let the duplication live for a while. If there is a pattern, it will become clear over time, and the proper abstraction will emerge from real evidence rather than a guess. But if the pattern never solidifies, you have lost nothing.
There is also an asymmetry that makes this more than a suggestion. Once you create a shared abstraction, every caller is coupled to it. As new callers are added, the coupling becomes stronger since any change needs to satisfy all of them. Splitting it back apart once there are a dozen consumers is hard, sometimes harder than the duplication you were trying to remove. Going the other way is much easier. Two similar things can be merged into one whenever you decide they really are the same.
When you are in doubt, it is better to keep the duplication. The price of being patient is small. Premature abstraction is expensive, paid over many years by many engineers in code that no one fully knows how to disentangle.
Sharing code across services: from library to microservice
Let’s make this concrete with a real-world example. Suppose we have two services in the system: payments and notifications. Both of them expose a public API, and both need to throttle clients to protect themselves from abuse. Team payments writes its own rate limiter inside the payments service. Team notifications does the same.
After a few months, the duplication becomes a pain. A bug in the token bucket logic gets fixed on the payments side, but it is not applied on the notifications side. At this point, someone suggests the obvious next step: let’s put the rate-limiting code into a shared component. The question is: what shape should that component take?
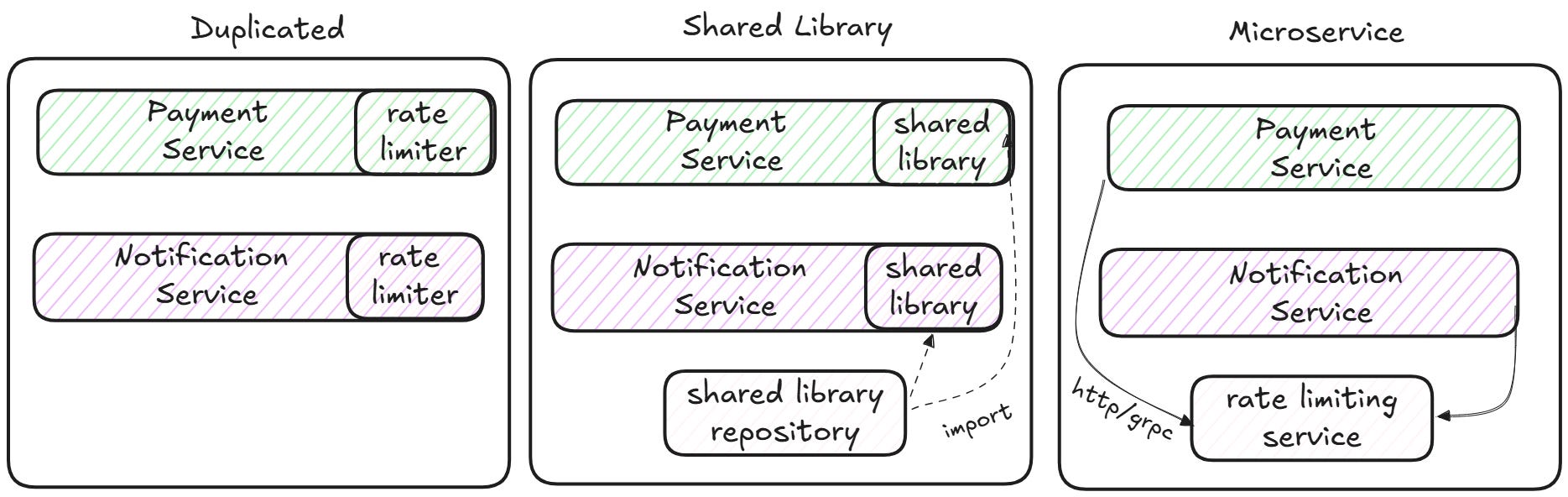
Option one is a library. Both services pull it in as a dependency. The rate limiter itself is in its own repo. This is the cheapest path. The fixed cost of setting up the library is small: a build, a versioning scheme, an artifact repository, and some documentation. Once it is in place, bug fixes are available to all clients at the next release. Both teams work on the same codebase, and knowledge spreads naturally.
However, a library is not a black box. When you import it, its code is included in your service, with all the consequences that follow. The first is the programming language. If payments is written in Go and notifications in Java, a shared library is not going to work. The second one is transitive dependencies. Your rate-limiting library pulls in a Redis client at version 4. The payments service uses another library that requires the Redis client to be version 6. Now everyone fights about which version wins, and the resolution rules of your build tool tell you which one to use. Debugging such conflicts can be tricky and may even turn off other teams from adopting your library in the first place. The right defensive move is to keep direct dependencies to a minimum, but the issue never really goes away.
In the end, libraries exchange duplication for coupling on the dependency level. The two services cannot evolve independently, but must agree on the language stack and tolerate each other’s transitive dependencies.
The second option is to extract rate limiting as its own microservice. Both clients now invoke an HTTP (or a gRPC) endpoint rather than importing a package. The boundary between services is an API, which is a cleaner contract than a binary dependency. The rate-limiting service can be deployed and scaled on its own. The team that owns it is free to change the implementation, as long as the API stays compatible. API evolution is also easier because you can measure endpoint usage and deprecate the ones nobody calls anymore.
However, this approach is more expensive. Each request for payments or notifications now makes an extra network call to the rate-limiting service. Latency budgets become tight, and you may need caching, retries, or speculative execution to meet your service-level agreements. If the dependency breaks, well, that is also your problem now. What should payments do if the rate-limiting service is down? Remain safe and decline all incoming requests, or accept them all and stay available?
Both decisions have implications, and you need to choose thoughtfully. On top of that, running a service has operational costs such as monitoring, on-call rotations, alerting, and capacity planning. The first one in particular is a serious investment.
To wrap up the comparison, a library is cheap and tightly coupled at the dependency level. A microservice is expensive and loosely coupled at the API level. There isn’t a universal answer. The choice depends on how complex the shared logic is, whether it really has its own business domain, what your latency requirements are, and whether your organization can afford another running service. The simpler the logic, the more likely a library is to be enough. The more independent and complex the domain is, the more a microservice starts to make sense.
The same tradeoff inside a codebase
The same tradeoff applies one step down. The standard mechanism for sharing code inside a single codebase is inheritance. You extract the common functionalities into a base class and let subclasses provide the specialized behavior. This is clean in theory, but has the same coupling cost as a shared library or shared service, just on a smaller scale.
Let’s stick with the notifications service from the previous section. Suppose it has to send messages over two different channels: email and SMS. Both channels need the same infrastructure: a buffer for outgoing messages, logic for retrying messages that fail temporarily, and batching for when traffic is high. The call that sends the message to the provider is the only real difference between them.
The textbook solution is to extract a BaseNotificationSender class with the buffering, retry, and batching logic, and let EmailSender and SmsSender extend it by adding only the send method. DRY is satisfied. Both classes look small and easy to read. Everyone is happy until the next change arrives.
Say marketing wants to run a large campaign and asks that SMS switch to unbounded buffering for the duration. Now we have an issue. The buffering logic is in the parent class, and the parent class is shared with email. We can’t change the behavior for SMS without changing it for email too, and email has good reasons to preserve its bounded buffer.
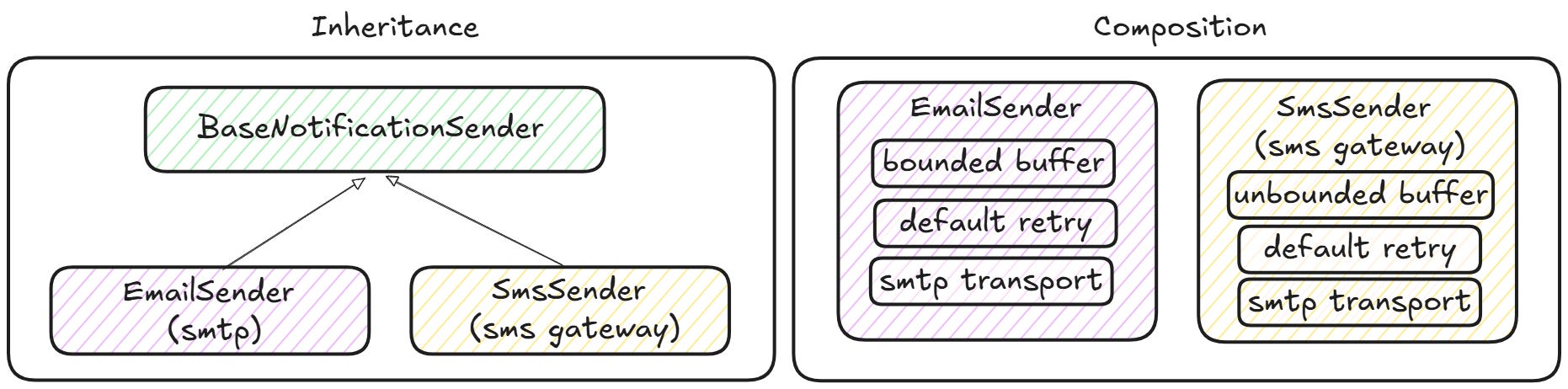
The instinct is to treat it as an exceptional situation. You could add an if statement in the parent class to check whether it is an instance of SmsSender, or pass a flag, or add a hook method. All these ways work, in the sense that they make the code compile and the campaign ship. But they also leak SMS-specific knowledge into the parent class, and the parent class no longer represents a clean abstraction. It is now a place where everyone’s special cases live. The next time a divergent change comes in for email, we do the same thing again. After a few iterations of this, the parent class gets harder to understand than the two duplicated subclasses would have been in the first place.
The takeaway is that inheritance is shared code with extra coupling. The moment one child needs to diverge, the abstraction starts to push back.
However, there is another approach to deal with this, which is composition. Instead of one inheritance hierarchy, you split the responsibilities into distinct pieces: a buffer, a retry policy, and a transport. Then you plumb them together. The email sender uses a bounded buffer with HTTP transport. The SMS sender uses an unbounded buffer and a different transport. The buffer is no longer coupled to the transport. The flexibility is real, and so is the cost: there are more moving parts to understand, and the reader has to hold more pieces in their head to follow what happens when a message is sent.
There is no free lunch. Inheritance is cheap and rigid. Composition is flexible but has more moving parts. The best choice really depends on the divergence you expect.
Closing thoughts
DRY is not wrong. It is just not free. If we remove duplication, the risk is that we pay for it somewhere else. These costs can be in the form of coordination issues between teams, dependency problems, extra network calls, or abstractions that get in the way when a new change comes in.
The skill is being able to tell when the coordination cost of sharing is higher than the maintenance cost of duplicating. And that calculation shifts as you cross boundaries.
Inside a small codebase owned by one team, DRY almost always wins. But across team boundaries, service boundaries, or tech stacks, the math gets less straightforward, and duplication can be the better answer.
There is one more thing worth keeping in mind. It’s much easier to merge two similar things later than to split a shared abstraction once it has a dozen callers depending on it. Going from duplicated to shared is easy to revert. Going from shared to duplicated is hard, sometimes harder than living with the duplication in the first place.
So when in doubt, let the duplication live. The right abstraction will emerge from real evidence, or it will not. Either way, you are better off than committing to the wrong one too early.
Obrigado pelo artigo. Quando pego seu artigo e uso I.A para me explicar como se fosse criança de 10 anos e peço casos de usos para usar com Laravel a compreensão se torna ainda mais fácil.
Very good. For the shared service part, there is even a idea named dead star which is exactly what happens when you share things too much. In short, in the long run, DRY introduces a level of interdependencies that will definetely slown you down.