
The Training Trap: Underfitting, Overfitting, and How to Escape Them
A practical guide to the most common problems in machine learning training and the techniques to solve them.

Hi Friends,
Welcome to the 179th issue of the Polymathic Engineer newsletter.
Regardless of whether you are an experienced machine learning practitioner or just a data scientist who has started their journey, you have surely had the same frustrating experience. You built a model, trained it on your data, everything looked fine, but then it fell apart in production.
There are two issues to be aware of. The first one is called underfitting. A model that underfits is too simple for the data. It makes many mistakes, even on the training data itself, because it can't capture the patterns underneath.
The second problem is called overfitting. This is the opposite of the first problem. In this situation, the model memorizes the training set perfectly; therefore, it can’t make generalizations.
In this article, we explore both underfitting and overfitting, as well as the methods to detect and address them. The outline is as follows:
What can go wrong when training a model?
Underfitting and overfitting: two sides of the same coin
Detecting the problem with testing
The golden rule and the validation set
The model complexity graph
Solving the problem: regularization
Measuring complexity: L1 and L2 norms
The regularization parameter
When to use L1 vs L2
Project-based learning is the best way to develop technical skills. CodeCrafters is an excellent platform for tackling exciting projects, such as building your own Redis, Kafka, a DNS server, SQLite, an HTTP server, or Git from scratch using your favorite programming language. Now you can also try to build your own Claude Code (for free, still in beta).
Sign up, and become a better software engineer.
What can go wrong when training a model?
Let’s try to answer this question starting with a simple analogy. Imagine you have to study for an exam. There are many things that could go wrong as you prepare.
You might not have studied enough. There is no way to fix that, and you are likely to perform poorly. But what if you studied a lot, just in the wrong way? For example, you choose to memorize the entire textbook word for word instead of trying to understand the material. Will you do well? Likely not, because you memorized everything without actually learning anything. You won’t know how to answer questions on the exam that you haven’t seen before.
The best approach is to study in a way that lets you answer questions you haven’t seen during your preparation.
The same things can go wrong with machine learning models. Not studying enough is like underfitting: the model is too simplistic to learn anything helpful from the input data. Memorizing the textbook is like overfitting: the model becomes too complicated and remembers the training data rather than learning the underlying patterns. A good model is one that learns the data properly and can make good predictions on new data it has never seen.
There is a fundamental trade-off in machine learning between finding the best model for the training data and ensuring it performs well with unseen data. Optimization is the process of tuning a model to work as well as possible on the training data. On the other hand, generalization is how well the model performs with data it has never seen before. The goal is always to generalize well, but there is a catch: you can only control the optimization. You adjust the model to fit the training data, and you hope it works well on other data. If you optimize too much, you can overfit, and generalization gets worse.
In the next section, we will look at underfitting and overfitting in more detail and see what they look like in practice.
Underfitting and overfitting: two sides of the same coin
A different way to look at underfitting and overfitting is through the lens of problem- solving. There are two mistakes you can make when you have a problem to solve. You can make the problem too simple and come up with an overly basic solution. Or you can overcomplicate the problem and come up with a solution that is too elaborate.
Imagine your task is to fix a leaking faucet. If you just put a bucket under it, you have oversimplified the problem. The faucet keeps dripping, and you are only catching the water, not fixing anything. This is underfitting: you are trying to model your data with something that is too simple to work effectively.
On the other hand, if you knock out all the plumbing in your house to fix a small drip, you have overcomplicated the solution. You may have fixed the leak, but this approach wasted resources and made the work more difficult than necessary. This is overfitting: your data might be simple, but you try to fit it with a model that is too complex. The model will fit the training data, but it will memorize it rather than learn from it.
Let’s look at a concrete example with polynomial regression. Suppose that you have a dataset that looks like a parabola, which is a curve that goes up and then down. You want to fit a polynomial to this data, but you don’t know what degree. Should you use a line, a quadratic, or something more complex?
If you fit a line (a polynomial of degree 1), the model is too simple. It is impossible for a straight line to capture the shape of a parabola, and the model underfits. If you fit a quadratic (a degree-2 polynomial), the model captures the essence of the data well. It neither underfits nor overfits. However, if you fit a polynomial of degree 10, the model becomes too flexible. It can bend and twist to reach each point in the dataset, but that is not the goal. Instead of learning that the shape looks like a parabola, it memorizes the exact positions of each point. The model overfits.
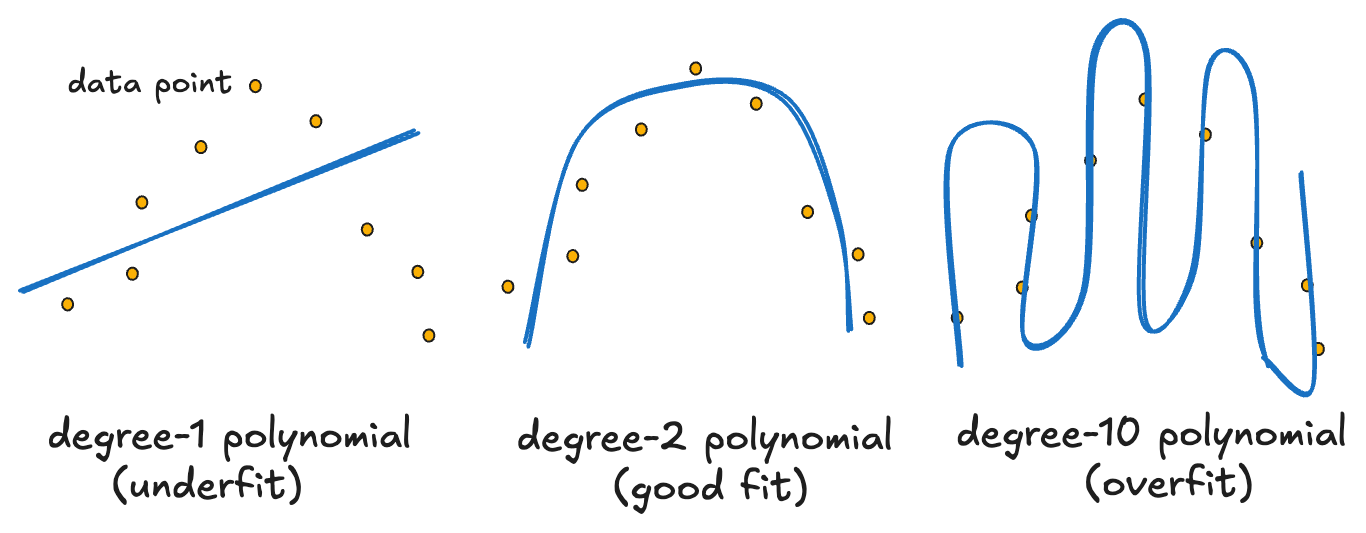
The real problem with overfitting shows up when you try to make predictions on new data. A model that memorized the training set will perform very poorly on data it has never seen before. It learned the noise and quirks in the training data, rather than the underlying pattern. Here is a simple way to tell what is happening with your model:
Underfitting: The model performs poorly on the training data and poorly on new data. It is too simple to learn anything useful.
Good fit: The model performs well on the training data and on new data. It has learned the underlying patterns.
Overfitting: The model performs very well on the training data but poorly on new data. It has memorized rather than learned.
But how can you actually measure this? How can you know if your model will perform well on new data before you deploy it? This is where testing and validation come in.