
The Building Blocks of Concurrent Programming
Understanding processes, threads, and how they communicate.

Hi Friends,
Welcome to the 163rd issue of the Polymathic Engineer newsletter.
Concurrent programming involves breaking down applications into separate units of work. These units, known as tasks, set up the execution flow of an application. At their core, tasks are just abstractions. At some point, they must eventually be mapped to the physical devices that execute the code.
Thank goodness, we don’t have to worry about this. The operating system, which is another layer of abstraction, handles this for us. Its role is to make the best use of the available hardware as possible, but it is not a magical box. Still, programmers need to organize their work in a way that helps the operating system use hardware in the best way possible.
In this article, we will discuss processes and threads, which are the two main building blocks of concurrency, and understand how they can talk to each other (Demo code in this GitHub repo).
The outline is as follows:
Processes
Threads
Processes vs Threads
Interprocess Communication
Message-Passing Mechanisms
The Thread Pool Pattern
Project-based learning is the best way to develop technical skills. CodeCrafters is an excellent platform for tackling exciting projects, such as building your own Redis, Kafka, a DNS server, SQLite, or Git from scratch. Sign up, and become a better software engineer.
Processes
The informal definition of a process is simple: it is a running program. A program by itself is just a file sitting on a disk. It contains a set of instructions, but it does nothing on its own. When the operating system takes those instructions and starts executing them on hardware, it becomes a process.
Think of it like a recipe in a cookbook. The recipe itself is just words on paper listing ingredients, steps, and timings. It doesn’t make anything by itself. But if a chef reads it and starts cooking, it becomes a meal in progress. Source code works the same way.
It is just a passive sequence of instructions. Developers write code using abstractions like memory, files, and network connections, but the actual resources must be given at runtime. The OS wraps all of this into what we call a process.
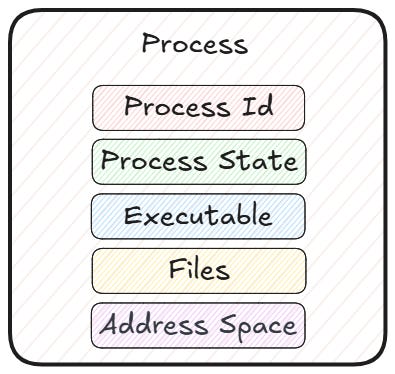
A process is made of several parts that the OS keeps track of:
Address space: the memory the process can see and access
Executable: the file with the machine instructions
Process ID (PID): a unique name to identify the process
Process state: whether it is running, waiting, or finished
Open files and connections: any resources the process is using
All of these together make up the execution context. Since so many things are packed into a process, starting a new one is a pretty heavy thing to do, and processes are often called heavyweight.
If you look at a process as a whole, its lifecycle is, its lifecycle is straightforward. First, it doesn’t exist. After that, the OS creates it and places it in memory (the Created state). From there, it moves to the Ready state: it can run at any moment, but the CPU hasn’t picked it up yet. When the OS scheduler selects it, the process goes into the Running state. Once it completes or fails, it reaches the Terminated state.
Creating and terminating a process is relatively expensive since so many resources are attached to it and must be assigned or released.
Processes can create their own processes, called child processes, using system calls like fork() or spawn(). This is called spawning. Each child process gets its own independent memory address space, which means it is completely isolated from the parent process and any other children.
This is where things get interesting for concurrency. By spawning multiple processes, we can split execution across them and run them simultaneously on parallel hardware.
However, the isolation is both a good and a bad thing. Since two processes don’t share much by default, communication between them requires special mechanisms, which are usually several orders of magnitude slower than direct memory access. We’ll talk about that more later in this article.
Threads
Most operating systems let you share memory between processes, but this takes extra effort. However, there is a different abstraction that lets you share memory and other kinds of resources in a simpler way: threads.
At the end of the day, a program is simply a list of machine instructions that must be carried out in the right order. The OS uses the concept of a thread to do this. A thread is an independent stream of instructions whose execution can be scheduled by the OS.
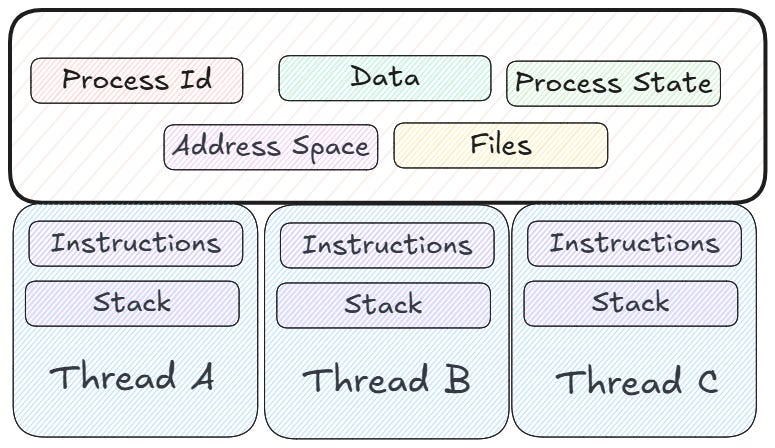
In the previous section, we said that a process is a running program plus resources. If we break that apart, a process is a container of resources (address space, files, network connections, and so on), while a thread is the dynamic part: the set of instructions that run inside that container. From the OS’s point of view, a process can be seen as a unit of resources, while a thread can be seen as a unit of execution.
The idea behind threads is that sharing a common address space is the most efficient way for processes to communicate. Threads in the same process can share resources (address space, files, connections, and data) with each other and their parent process, in an easy way.
Each thread also keeps its own state to allow for safe, local, independent execution of its instructions. Each thread is unaware of the other threads unless it is trying to mess with them on purpose. The OS manages threads and distributes them across available processor cores. This makes a multithreaded program an effective way to run multiple tasks concurrently.
Historically, hardware vendors implemented their own versions of threads, and these implementations were quite different. This made it challenging for programmers to write portable multithreaded applications. For UNIX systems, IEEE POSIX defined a standard programming interface. Implementations that follow this standard are called POSIX threads or Pthreads.
Every program we run causes the OS to create a process, and every process has at least one thread. A process without a thread cannot exist. When we start a program, a main execution thread is created. Any thread, even the main one, can create child threads at any time.
Threads have much less memory overhead than the standard fork() function. Since threads use the same process, nothing is copied. This is one reason why threads are sometimes called “lightweight processes.” It takes less time for the OS to assign and handle thread resources, plus starting and ending threads is faster than starting and ending processes.
However, there is a catch. The OS provides complete independence of processes from each other, so if one of them crashes, other processes are not harmed. This is not true for threads. All threads in a process use the same shared resources, so if one crashes or messes up something, it’s likely that the others will too. To avoid this, programmers need to make sure that shared resources are only used by one thread at a time and give them more control over how threads behave.
Processes vs Threads
To illustrate the difference between processes and threads, let’s go back to our recipe example. Imagine you run a restaurant and need to prepare three different dishes.