
Range Queries
How to quickly calculate range queries on arrays using prefix sum and sparse tables.

Hi Friends,
Welcome to the 126th issue of the Polymathic Engineer newsletter.
This week, we discuss some interesting data structures that can be used to efficiently run range queries on arrays. In particular, we will mostly talk about range sum queries (which add up all the elements in a range) and range minimum queries (which find the lowest element).
The outline will be as follows:
What are range queries?
Sum queries with prefix sum
Prefix sum for 2D subarrays
Minimum queries with sparse table
Classic problems
The Fastest Open Source Analytics Database, Fully Managed
This issue is offered by Aiven for ClickHouse®, the fully managed service for your real-time data warehouse and open-source database needs. ClickHouse lets you process analytical queries 100-1000x faster than traditional row-oriented systems. Spin up clusters in minutes, scale, fork and migrate – all from a single dashboard – and let Aiven handle the rest.
Try Aiven for ClickHouse® and Get a $100 Credit After the Free Trial

What are range queries?
Range queries are operations that retrieve and/or process information from a specific interval within an array. The array usually has numbers in it, and we want to find the sum, minimum, maximum, or average of all the numbers in any subarray.
For example, given an array of stock prices, a range query might ask, "What was the lowest price between day 10 and day 20?" Or, "What was the average price between day 15 and day 25?"
The simplest thing to do would be to go through each element and calculate step by step the information you need. However, calculating results for every query over and over again is a waste of time, especially when working with big datasets.
If the array values don't change between queries, it's better to preprocess the data so that it can be quickly returned to future queries.
In the following sections, we'll dig into the sum and minimum range query types. For each of them, we will see how to build and use specialized data structures that can answer queries in constant time after the initial preprocessing.
Sum queries with prefix sum
The goal of sum queries is to figure out the sum of all elements in a certain range of an array. To quickly answer, we can use a data structure called prefix sum.
A prefix sum is a precomputed array where each element is the sum of all elements up to that index in the original array.
Here's how to construct it:
Start with the original array: [1,6,5,4,8,3,4,2,1,5]
Create a new array of the same length
The first element is the same as in the original array
Each subsequent element is the sum of itself and all previous elements
The resulting prefix sum array would be: [1,7,12,16,24,27,31,33,34,39].

With a prefix sum array, we can calculate the sum of any range [i, j] in constant time using this formula:
sum(i, j) = prefix[j] - prefix[i-1] (if i > 0)
sum(i, j) = prefix[j] (if i = 0)
For example, to find the sum of elements from index 4 to 7 in our original array:
sum(4, 7) = prefix[7] - prefix[3] = 33- 16 = 17.
Here is a code snippet that implement the approach:
def answer_queries(nums, queries, limit):
prefix = [nums[0]]
for i in range(1, len(nums)):
prefix.append(nums[i] + prefix[-1])
ans = []
for x, y in queries:
curr = prefix[y] - prefix[x] + nums[x]
ans.append(curr < limit)
return ansWithout the prefix sum, we would need to iterate through the range for each query in O(n) time. With prefix sum, after the O(n) preprocessing to build the array, each query takes O(1) time. This is a significant improvement for multiple queries on the same array.
Prefix sum for 2D subarrays
The concept of prefix sum can be extended to 2D grids or matrices allowing us to efficiently calculate the sum of any rectangular subarray.
In a 2D prefix sum array, each element (i, j) represents the sum of all elements in the rectangle from (0, 0) to (i, j) in the original array. Build the array is straightforward:
Start with the original 2D array
Create a new 2D array with an extra row and column of zeros (useful to avoid writing specific code to handle queries on the first row and column)
Fill the array using the formula:
prefix[i][j] = original[i-1][j-1] + prefix[i-1][j] + prefix[i][j-1] - prefix[i-1][j-1]
Once the array has been built, the sum of a rectangular subarray rom (r1, c1) to (r2, c2) can be calculated using the formula:
sum = prefix[r2+1][c2+1] - prefix[r1][c2+1] - prefix[r2+1][c1] + prefix[r1][c1]
This following diagram shows how the formula effectively subtracts the areas that we don't want to include and adds back the overlapping area that was subtracted twice.

Minimum Queries with Sparse Table
While sum queries are helpful in many scenarios, sometimes we need to find the minimum (or maximum) value in a given range of an array.
This is where minimum queries come into play. We can't use a simple prefix-based approach here, but we need a more complex data structure known as a sparse table.
The idea is to build a table T where each cell (i, j) stores the minimum value for the range starting at index i with length 2^j.
In the first row of the table, every element represents itself. In the subsequent rows, the values are set according to the formula T[i][j] = min(T[i][j-1], T[i + 2^(j-1)][j-1]).

Once we've managed to build the table, we can find the minimum in the range [L, R] using two overlapping ranges whose union covers [L, R].
The idea is to the largest power of 2 not exceeding the length of the range (R - L + 1), and calculate the answer according to the formula:
min ( sparseTable [j] [L], sparseTable [j] [R - (2^j) + 1] )
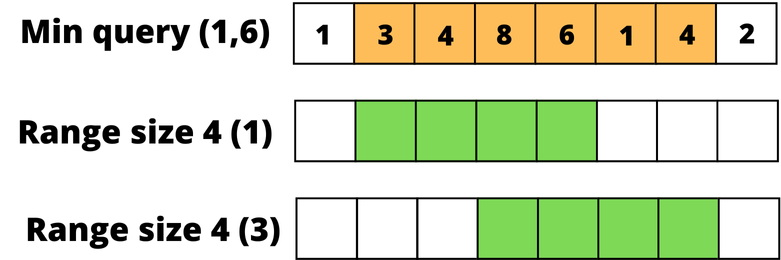
This method allows us to answer minimum range queries in O(1) time after O(n log n) preprocessing. The reason why building the table takes O(n log n) is that there are log(n) ranges having a length that is power of two.
Classic Problems
Let's look at some examples of range sum query problems to better understand how the approaches we discussed work in practice.
Range Sum Query - Immutable and Range Sum Query 2D - Immutable are the classic application of prefix sum arrays. Given an array or matrix and multiple queries asking for the sum of elements in a range, we can use prefix sums to answer each query in O (1) time after preprocessing.
class NumArray:
def __init__(self, nums: List[int]):
self.prefix_sum = [0]
for num in nums:
self.prefix_sum.append(num + self.prefix_sum[-1])
def sumRange(self, left: int, right: int) -> int:
return self.prefix_sum[right + 1] - self.prefix_sum[left]The Find Pivot Index problem takes an array of integers as input and asks for its pivot index. The pivot is the lower index where the sum of all the numbers strictly to the left is equal to the sum strictly to the right. If there is no such index, the returned result should be -1.
A great way to reformulate the problem is using the concept of the prefix sum. Indeed the searched index is the lower index i, such as the prefix sum of the element before i is equal to the postfix sum after i.
Prefix and postfix sum can be calculated while iterating through the input array. The prefix sum is the sum of all the elements preceding the current one. The postfix sum is the difference between the sum of all the elements and the prefix sum plus the current element.
Take a look at how the following code used the idea of a prefix sum without actually building the prefix sum array. We can use an integer instead of an array to do the same thing because we only need to access the left sum incrementally.
def pivotIndex(nums):
total_sum = sum(nums)
left_sum = 0
for i, num in enumerate(nums):
if left_sum == total_sum - left_sum - num:
return i
left_sum += num
return -1Another interesting problem is Number of Ways to Split Array. The problem asks for the number of ways to split an array into two non-empty subarrays such that the sum of the left subarray is greater than or equal to the sum of the right subarray.
Prefix sum allows us to calculate the sum of every possible left subarray and compare it with the corresponding right subarray in O(1) time, giving us a linear time solution overall.
def waysToSplitArray(nums):
count = 0
total = sum(nums)
left_sum = 0
for i in range(len(nums) - 1):
left_sum += nums[i]
right_sum = total - left_sum
if left_sum >= right_sum:
count += 1
return countSubarray Sum Equals K is a slightly more difficult problem that asks for the number of subarrays whose sum equals a given value K.
The naive approach would be to consider every possible subarray and check if its sum equals k. However, this solution has a time complexity of O(n²) because of a nested loops: the outer loop iterates through all possible starting points, and the inner loop iterates through all possible ending points for each starting point.
The key insight is that we can use prefix sums to check more efficiently if a subarray sums to k. If we have a prefix sum array where prefix[i] is the sum of elements from index 0 to i, then the sum of elements from index i to j is:
sum(i,j) = prefix[j] - prefix[i-1]
In our case, we're looking for subarrays where
prefix[j] - prefix[i-1] = k or prefix[i-1] = prefix[j] - k
This means that if we're at index j with a prefix sum of prefix[j], we need to find how many previous prefix sums equal (prefix[j] - k). Using a hash table to keep track of the frequency of each prefix sum, we can solve the problem in O(n) time.
def subarraySum(nums, k):
count = 0
prefix_sum = 0
# This hashmap stores the frequency of each prefix sum we've seen
prefix_counts = {0: 1} # Handle subarrays starting from index 0
for num in nums:
prefix_sum += num
if prefix_sum - k in prefix_counts:
count += prefix_counts[prefix_sum - k]
# Update the frequency of the current prefix sum
prefix_counts[prefix_sum] = prefix_counts.get(prefix_sum, 0) + 1
return countInteresting Reads
Some interesting articles I read this week:
Interesting article Fernando!
What’s the idea behind having Range 4 and 8 beyond Range 2? What would be the application of this?
Thanks for mentioning my writing 🙂
Loved this breakdown, Fernando, super clear!
One thing that came to mind: in real-world systems, range queries don’t just live in algorithms; they hit storage too.
Things like Parquet files or data skipping indexes can really speed up scans.
It would be cool to hear your take on how these ideas play out when infrastructure comes into the picture.
Also, thanks for the mention!