
Linear Time Sorting
Why comparison based algorithms cannot sort in less than O(nlogn). And why counting sort, radix sort and bucket sort can do better.


Hi Friends,
Welcome to the 65th issue of the Polymathic Engineer newsletter. This week, we discuss algorithms capable of sorting array elements in linear time.
The outline will be as follows:
Performance limits of comparison-based algorithms
Counting Sort
Radix Sort
Bucket Sort
Interesting posts
Performance limits of comparison algorithms
The most popular sorting methods, like heapsort, mergesort, and quicksort, belong to a category known as comparison-based algorithms. Such algorithms don’t make any assumptions about the items but sort by comparing them to each other.
Given two array elements, x and y, they perform one of the tests x < y, x <= y, x > y, or x >= y to determine their relative order. Considering this, comparison-based algorithms have a time complexity that is not lower than O(n log n), where n is the size of the array.
Formal proof of this would be too cumbersome, but it’s easy to develop intuitive proof based on tree theory. The behavior of a comparison-based algorithm can be visualized using a full binary tree representing the comparisons between the array items.
Such a tree is called a decision tree. Each node of the tree represents a comparison between two array items.
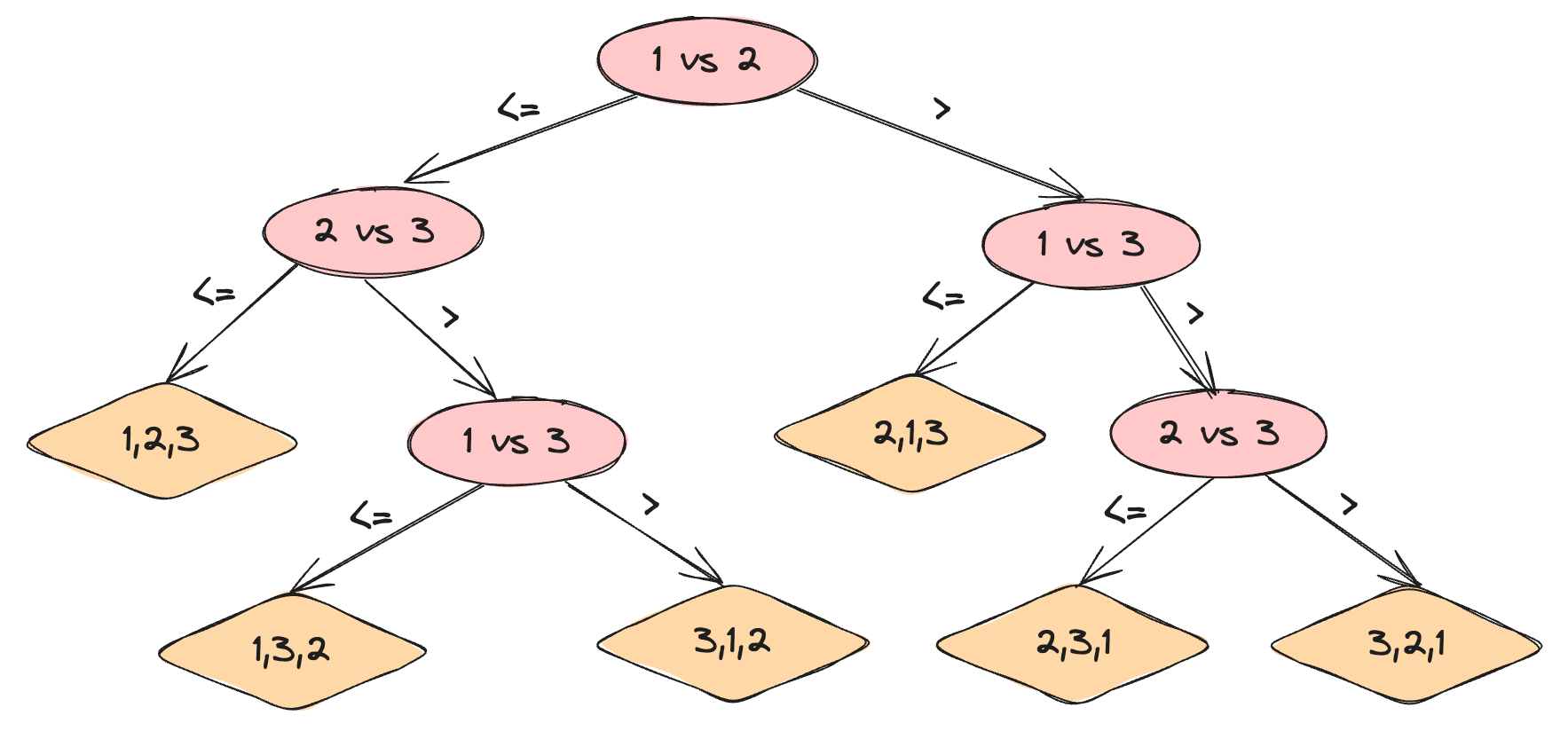
Because any sorting algorithm must be able to generate all permutations of its input, each of the n! permutations of the n array items must appear as one of the decision tree leaves.
Each leaf must be reachable from the root by a path corresponding to an algorithm's execution. The longest path from the root of a decision tree to any of its leaves represents the worst-case number of comparisons the sorting algorithm performs.
Since the number of leaves is at least n! and a binary tree of height h has no more than 2^h leaves, we can write that 2^h >= n!. In terms of logarithms, this means that h >= log(n!) and then that h = O(nlogn).
In the remaining section, we will analyze some algorithms that are not comparison-based and make some assumptions about the items to sort. This will allow us to sort the items in O(n) instead of O(nlogn).
Counting Sort
Counting sort is an algorithm that assumes the input items have integer keys in a limited range. The intuition is to count the frequency of each key and then place the corresponding items in their correct positions based on their values and frequencies.
Assuming that the input array contains only keys, the steps for implementing Counting Sort are as follows:
Create a hash table that maps keys with the frequency of the corresponding element.
Iterate over the input array to find the minimum and maximum keys.
Iterate over the input array and increase the frequency of each key in the counting hash map.
Iterate over the range from the minimum to the maximum key and place each element in its proper position in the original array based on the frequency in the hash map.
def countingSort(self, nums: List[int]) -> List[int]:
min_value = min(nums)
max_value = max(nums)
frequencies = defaultdict(int)
for num in nums:
frequencies[num] += 1
w = 0
for num in range(min_value,max_value+1):
if (count := frequencies.get(num, 0)) > 0:
for _ in range(count):
nums[w] = num
w += 1
return numsAs we discussed in the issue number 4, the implementation shall be slightly modified when the input array contains items associated to the keys.
The time complexity of the algorithm is O(n+k) where n is the size of the input array , and k is the range of the keys.
The O(n) part is because we need to iterate on the array items while counting the frequency and finding minimum and maximum values. The O(k) part is because we need to iterate on the key range to place the items in the correct position.
The space complexity is O(n) since the hash table may store O(n) items in the worst case.
Radix Sort
Radix sort also assumes the input items have integer keys. Different from counting sort, it takes advantage of the fact that integers have a finite number of digits, and each digit can have a limited number of values (0 to 9).
Instead of comparing elements, it sorts elements by the individual digits of the integers, starting from the least significant digit.
The steps for implementing Radix Sort are as follows:
Sort the array multiple times for each place value (unit place to last place)
For each iteration, create a bucket for each digit, push the keys in their respective bucket, and fetch them from each bucket one by one in the same order they were pushed.
Sort the array considering all elements are positive, and then we will separate the negative elements at the end in reversed order.
def radixSort(self, nums: List[int]) -> List[int]:
max_value = max(nums)
digit = 1
while digit < max_value:
buckets = [[] for i in range(10)]
for num in nums:
# abs allows to sort negatives in reverse order
index = (abs(num) // digit) % 10
buckets[index].append(num)
w = 0
for bucket in buckets:
for num in bucket:
nums[w] = num
w += 1
digit *= 10
positives = [n for n in nums if n >= 0]
negatives = [n for n in nums if n < 0]
negatives.reverse()
return negatives + positivesThe algorithm's time complexity is O(d⋅(n+b)), where n is the size of the input array, and b is the number of digits.
The O(n+d) part is because for each sorting iteration, we iterate over all the n input items to put them into the buckets, and then we iterate over the k buckets to put the item in the sorted order. The O(d) part is because we perform d sorting iterations.
The space complexity is O(n) because we store the n items in the buckets.
Bucket Sort
Bucket sort assumes that the keys are uniformly and independently distributed over a range of values. The idea is to divide this interval into n equal-sized subintervals, or buckets, and then distribute the n keys into the buckets.
Since the input items are uniformly and independently distributed, not too many keys fall into each bucket. To produce the output, we sort the keys in each bucket and then pull the keys from the buckets in order.
The keys in each bucket can be sorted using a standard comparison-based algorithm.
def bucketSort(self, nums: List[int], bucket_count: int = 10) -> List[int]:
if len(nums) <= 1:
return nums
min_value = min(nums)
max_value = max(nums)
bucket_size = max_value-min_value // bucket_count
buckets = [[] for _ in range(bucket_count)]
for num in nums:
index = (num - min_value) // bucket_size
buckets[index].append(num)
return [num for bucket in buckets for num in sorted(bucket)]Interesting posts
Diversification is what makes you understand how things work. Become an expert in a primary skill and build other secondary skills around it. Link
There is no time frame to become a good developer. Everyone's circumstances are different. But it is always worth applying for a job if you like it. The worst-case scenario if you apply is equal to the best-case scenario if you don't apply. Link
Are we supposed to be T shaped employees or V shaped employees?
Reagrding the statement "The intuition is to count the frequency of each key and then place the corresponding items in their correct positions based on their values and frequencies. " in counting sort section, is it frequency of keys or items.