
How to Stop Failures from Spreading Between Services
Practical patterns to protect your services from failing dependencies and excessive load.

Hi Friends,
Welcome to the 171st issue of the Polymathic Engineer newsletter.
In one of our previous articles, we looked at the most common root causes of failures in distributed systems and how to use redundancy and fault isolation to contain them. These are protections at the architectural level, which means they work based on how you design and deploy your system.
In this article, we are going to talk about something more tactical. We will discuss the patterns that stop faults from spreading from one service to another at runtime. These are techniques you can apply to existing systems with little effort.
The article is split into two parts. The first covers patterns that protect a service when one of its dependencies fails or slows down (downstream resiliency mechanisms). The second covers patterns that protect a service when its callers send more traffic than it can handle (upstream resiliency mechanisms).
The outline is as follows:
Timeouts
Retries
Circuit breakers
Load shedding
Load leveling
Rate limiting
Constant work
Project-based learning is the best way to develop technical skills. CodeCrafters is an excellent platform for tackling exciting projects, such as building your own Redis, Kafka, a DNS server, SQLite, HTTP server or Git from scratch using your favourite programming language. Noe you can also try to build your own Claude Code (for free, still in beta).
Sign up, and become a better software engineer.
Timeouts
When one service makes a network call, it should always set a timeout. The call fails if no response comes back within a certain amount of time. Without a timeout, the call might never return, and as we already discussed in the previous article, network calls that don’t return lead to resource leaks. Timeouts are the first protection you can use to find connectivity faults and stop them from cascading from one service to another.
You might think that setting timeouts is such a simple task that all network libraries do it for you, but that's not the case. When JavaScript's fetch API came out, there was no way to specify a timeout. Go's HTTP package doesn't employ timeouts by default, and the default timeout for the most popular Python library is infinity. Modern HTTP clients for Java and .NET do a better job and often come with default timeouts, but it's still a good idea to set them manually every time.
There is a golden rule here: always set timeouts when making network calls, and keep a close eye on third-party libraries that make network calls but don’t let you configure a timeout. But how do you pick a good timeout value?
One method is to base it on how many false timeouts you are okay with. For example, if you don’t mind 0.1% of requests timing out even though they would have worked in the end, you can set the timeout according to the 99.9th percentile of the downstream service’s response time.
It is also important to have good monitoring in place to measure the full lifecycle of a network call. This allows you to check how long a network call took, what status code came back, and if it timed out. Without this kind of visibility at the points where your system is integrated, it's much harder to figure out what's wrong with production.
To avoid repeating the same timeout and monitoring logic everywhere, you can wrap the network call in a library that does both. Another option is a sidecar proxy running on the same machine. This proxy will intercept remote calls and take care of timeouts and monitoring for you.
Retries
When a network call fails or times out, the caller can either give up or try again. If the failure was caused by a short-lived connectivity issue, retrying after a short wait has a good chance of working. However, retrying immediately will make things worse if the downstream service is already too busy,
This is why retries should be slowed down. The most frequent strategy is exponential backoff, in which the delay between retries increases with each attempt. For example, if the initial wait is 2 seconds and you double it each time with an 8-second cap, the delays will be 2, 4, 8, 8, 8... seconds.
This is why retries need to be slowed down. The most common method is exponential backoff, in which the delay between retries increases with each attempt. For example, if the initial wait is 2 seconds and you double it each time with a cap at 8 seconds, the delays would be 2, 4, 8, 8, 8... seconds.
Exponential backoff is helpful, but it has a problem. When a downstream service goes down temporarily, many callers’ requests will fail at the same time. They all retry on a similar schedule, which will cause the downstream service to experience load spikes that make things worse. To fix this, you can add some random jitter to the delay. This spreads out the retries over time and reduces the load on the struggling service.
Actively retrying right away isn’t always the only option, either. In batch systems that don’t need an immediate response, a failed request can be put into a retry queue. The same process, or a different one, can pick it up later and try again.
Additionally, not every failure is worth trying again. If the error isn’t temporary, such as the caller not being allowed to access the destination, retrying will fail again. If that is the case, the service should stop retrying right away. Also, if the network call is not idempotent, retrying can cause problems that affect the correctness of the application.
A last problem that is easy to overlook is retries amplification. Let’s suppose you have a chain of three services: the user calls service A, A calls service B, and B calls another service C. If the call from B to C fails, service B retries. But in the meantime, A sees a longer response time. If A times out, it retries too, and this adds even more load to the chain. If the user’s client also has retries, the total number of requests goes up quickly.
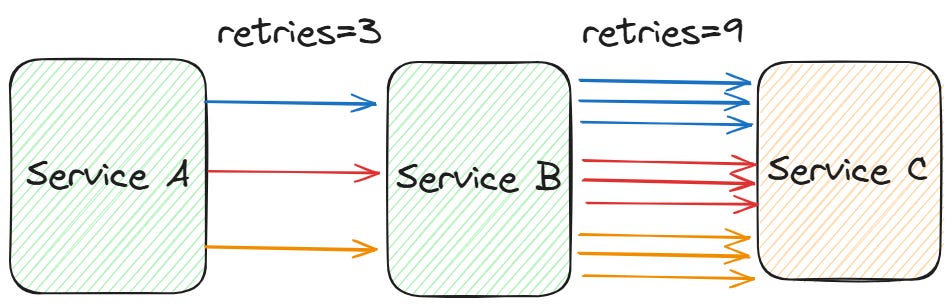
This amplification effect puts more pressure on a service the further down the chain it is. If you have large dependence chains, it is safer to only retry at one level and fail fast at all the others.
Circuit Breakers
Timeouts help you find when a downstream service is slow or unreachable, and retries help you get past short-lived failures. But what if the failure doesn't go away quickly?