
How to design a system for scale
Three different approaches to scalability: adding server clones, functional partitioning, and data partitioning.

Hi Friends,
Welcome to the 88th issue of the Polymathic Engineer.
Designing systems that can work on a large scale is a hard yet critical skill for software engineers.
As your application grows and your user base gets bigger, the ability to handle increased load becomes increasingly important.
This week, we'll explore three key techniques for creating scalable systems that can grow with your needs.
Whether working at a small startup or a large company, understanding these approaches and their pros and cons will help you design more robust and flexible solutions.
The outline will be as follows:
Adding server clones
Partitioning servers by functionality
Partitioning data
Project-based learning is the best way to build technical skills. CodeCrafters is an awesome platform to practice interesting projects like building your own Redis, HTTP server, and even Git from scratch.
Sign up, and become a better software engineer.
Adding server clones
Adding clones is the simplest and least expensive way to scale a system from scratch.
This technique involves creating exact copies of your existing servers or components, allowing them to share the incoming load.

The key to this approach is ensuring that each clone is interchangeable. Any request should be able to go to any server and get the correct result.
You can typically use a load balancer to distribute requests among your clones. This component acts as a traffic cop, directing incoming requests to the available servers.
While this method is effective, it works best with stateless services. In such a setup, each request is independent, and servers don't need to keep track of the previous interactions. This makes it easy to add/remove servers to/from the pool without worrying about syncing their state.
In the ideal case, the load balancer should be able to send a request to any server without looking back at where the last request went.
While you can scale your servers also vertically by upgrading their hardware, adding clones is a form of horizontal scaling which its often more flexible and cost-effective, especially in cloud environments.
The main challenge with this approach is handling stateful services. If you have an application that needs to remember information between requests, you need to find ways to synchronize this state across all the server clones.
Welcome to the 88th issue of the Polymathic Engineer newsletter.
Partitioning servers by functionality
Functional partitioning is a more advanced and flexible way to scale. This technique involves breaking your system into smaller and independent components. Each component is in charge of a specific functionality.
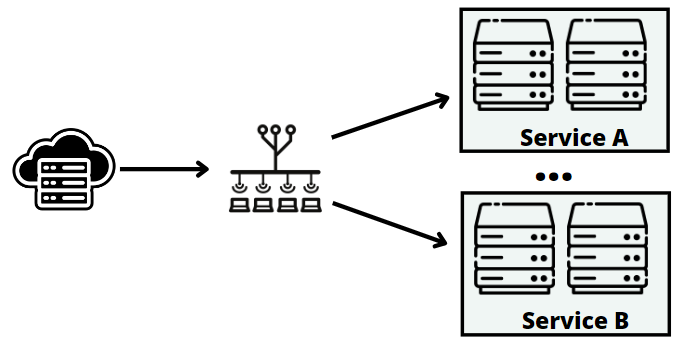
The approach is versatile, and you can apply it at various levels of abstraction.
From an infrastructure point of view, functional partitioning is about isolating different server roles. For instance, you might have separate servers for caching, storing data, message queues, and web services.
By doing this, you can scale these servers separately, giving resources where they're needed since their scalability needs will likely differ.
At a higher level of abstraction, functional partitioning means making applications or microservices that can run on their own.
For example, in an e-commerce application, you may have a profile service, a catalog service, a shopping cart service, and so on.
This way, multiple teams can work on different services at the same time without getting in the way of each other and can use the technology stack that works best for them.
The main challenge is that functional partitioning requires more management and initial effort. Moreover, there's a limit to how much you can partition your system before it becomes too complex.
Data Partitioning
A third approach for scaling systems is dividing your dataset and distributing it across multiple machines, each having a subset of the data.
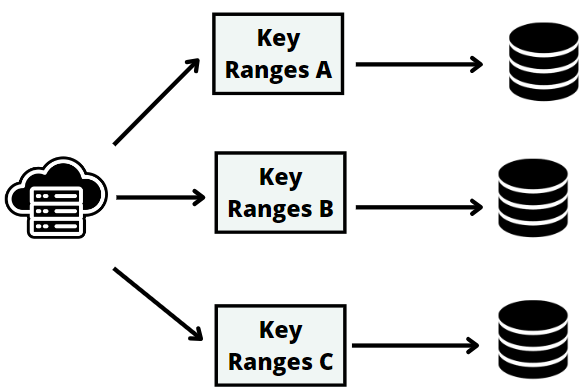
For example, if you have an e-commerce application with many users, you could split the user data on multiple servers. You can partition by username or use more sophisticated partitioning schemas, but the principle remains the same.
This setup has several benefits. It speeds up data processing and storage as each server only has to deal with a smaller amount of data at a time and can store more data in memory.
It also makes the system scalable, so as the amount of data grows, you can add more servers and change how the data is distributed between them.
Data partitioning, when done right, can allow for endless scalability. However, it's not a piece of cake. Data partitioning is complex and can be expensive to set up.
You need a system to track where each piece of data is stored to direct queries to the correct server. In addition, it can be hard to make queries that cover more than one data partition and work well.
Food for thoughts
A team of professional developers who work well together is better than a rockstar developer who thinks to solve everything alone.

As a parent, flexibility is one of the most important benefits you can get. Flexible hours and reasonable meeting times can do a lot to reduce stress and increase productivity.

There are some big pros in working at big tech companies like the compensation you get and the reputation you build. On the other hand you can find great teammates and working conditions also in many other companies. Link

DSA for backend engineers
Some time ago I've been invited to the Mastering Backend podcast to talk about why data structures and algorithms knowledge is important for backend engineers. If you're interested, you can watch the whole episode here.
Interesting reads
A few interesting articles I read in the past days:
Just a small note, hexagonal and code to win articles links are broken :)
Great work here Fernando!
You have made it very simple for anyone to understand how should scaling be achieved.