
How machine learning and optimization work well together
From making predictions to making choices.


Hi Friends,
Today’s special issue features a guest post from Tim Varelmann, founder of Bluebird Optimization. Tim is a reader of our newsletter. He contacted me to ask if there was an opportunity to collaborate on the newsletter as a guest author for an issue, and I gladly agreed because I think what he has to say could be interesting to you all.
Tim develops optimization software that helps planners of core business operations make sound, data-driven decisions. He holds a PhD in optimization, with studies at RWTH Aachen, UT Austin, University of Queensland, and MIT, and has combined machine learning and optimization in innovative ways across multiple client projects.
He is also the author of the world’s first course on GAMSPy (“Effortless Modeling in Python with GAMSPy”). If you want a practical framework for combining ML and optimization from Tim, you can find it here. Now, over to Tim.
Your AI shouldn’t grade its own homework
Claude Code writes beautiful code. So does Codex. But here’s the thing, they also think they write beautiful code. And when you ask an AI to review code it just wrote, you get the intellectual equivalent of a student grading their own exam. Shockingly, they always pass.
CodeRabbit CLI plugs into Claude Code and Codex as an external reviewer, different AI Agent, different architecture, 40+ static analyzers, and zero emotional attachment to the code it’s looking at. The agent writes, CodeRabbit reviews, and the agent fixes. Loop until clean.
You show up when there is actually something worth approving.
One command. Autonomous generate-review-iterate cycles. The AI still does the work. It just doesn’t get to decide if the work is good anymore.
Free tier available. Try CodeRabbit’s CLI.
Thanks to the CodeRabbit team for collaborating with me on this newsletter issue.
Machine learning and optimization
Every day, you make a lot of decisions based on information that doesn’t actually tell you what to do. Your navigation app knows there will be heavy traffic at 8 am. That is a prediction. What you do about it is a decision that depends on things the app knows nothing about.
Can you move your first meeting? Is the alternative route through the school zone worth it? Is today the day you finally just work from home? The same forecast, ten different people, ten different choices.
A big part of our job as engineers is finding an appropriate solution to a problem.
Netflix works differently. It predicts how much you will enjoy each show in its catalog (typically using Machine Learning). And from that prediction, the decision about what to recommend to you is almost mechanical: sort by the probability that you will like a show, and fill the three recommendation slots with the top results. Here, knowing the forecast basically means knowing the answer.
Most real-world problems sit somewhere between these two. Predictions matter a lot. But constraints, trade-offs, and competing priorities sit between the forecast and the action. The gap between them is exactly where machine learning and mathematical optimization (or operations research) have to work together.
A forecast tells you what the world looks like. It takes something else to decide what to do in it.
In my experience, the combinations that actually work follow a small number of recurring patterns. Let me show you three of them.
Three Combinations of ML & Optimization
I keep seeing the same structural roles in different fields, even when applications look very different at first glance:
Making good decisions in the face of uncertain futures
Replacing math that is difficult to compute with clearly structured ML models
Optimizing systems where no physical laws exist, only observed behavior
There is a fourth pattern where machine learning is used inside optimization solvers themselves, helping them make internal algorithmic choices. This requires deep solver-internal knowledge, which I do not want to presume here. The three patterns above already provide plenty of substance.
Let’s start with the most important one.
Pattern 1: Making good decisions when the future is uncertain
Inventory management makes this pattern very clear. Some products sell at a steady rate. Others barely move for weeks, then suddenly spike. Imagine two spare parts with the same average annual demand. On paper, they look identical. In reality, you should manage them very differently.
The danger of a single number
Here is the problem: rich information often dies somewhere between the ML forecast and the optimization model. A probabilistic forecast (one that shows you a whole range of possible futures) gets boiled down to one number, the expected value, before the optimizer ever sees it. This is poison for the combination of ML and optimization.
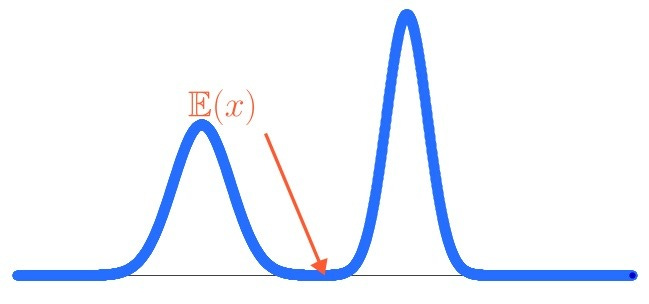
Modern ML models are naturally good at producing rich outputs. Distributions. Confidence intervals. Samples from possible futures. That is exactly the information the optimizer needs. Throwing it away and handing over just the average is like hiring a weather forecaster and only asking them whether it will rain - yes or no.
What optimization can do with the full picture?
With the full distribution, the optimizer can distinguish between the two spare parts, even though their averages match.
For the part with steady demand: order just-in-time, keep safety stock lean.
For the part with spiky demand: an inventory manager might consciously accept a 10% stockout risk during high-demand phases, if that means avoiding expensive external storage. Maybe that trade-off makes financial sense. Maybe a 15% risk of stockout does not, and the cost for external storage would be preferable. The optimizer finds that line. Without the probabilistic input, it cannot even see the question.
Where it works - and where it breaks
This pattern shines when:
Decisions have asymmetric consequences. A missing safety-critical spare part that shuts down a production line is a very different problem from a surplus of optional accessories gathering dust.
Different futures require fundamentally different responses. Two parts with the same average demand but different distributions need different inventory strategies.
Performance must be robust, not just good on average. If a part is both spiky and safety-critical, you might want guaranteed coverage across two consecutive demand spikes - even if that means holding more stock most of the time.
It breaks when uncertainty gets collapsed too early. If the optimizer only sees one number, it will make one-size-fits-all decisions - and quietly leave money on the table.
Pattern 2: Replacing math that is difficult to compute with clearly structured ML models
Sometimes the core difficulty is not uncertainty, but complexity. As a researcher, I worked on optimization problems involving air separation units. These are industrial plants that cool air to extremely low temperatures. Oxygen liquefies slightly before nitrogen, so this liquefaction helps separate oxygen from nitrogen.
The physics involved is well known, but it is also very nonlinear and hard to calculate. Also, these equations are already approximations of the quantum-chemical truth of the world. So, in optimization, the real question wasn’t whether the equations were “true,” but whether they could be used to solve a big optimization problem.
In that case, my coworkers replaced the detailed thermodynamic relationships with a neural network trained on simulation data.
The neural network introduced a small additional approximation error, which was acceptable. In return, the computations became much easier. The optimizer now saw a clean, repeated structure it could work with efficiently.
The win was structure instead of chaos.
Where this pattern works - and where it breaks
This pattern is particularly powerful when:
Some difficult equations are already approximations, so an additional approximation is not as problematic
The true slowdown is computational difficulty, not physical accuracy
It breaks when surrogate models are forced to extrapolate beyond their training data, or when critical structural properties of the original equations are lost in the approximation.
Pattern 3: Optimizing systems where no physical laws exist, only observed behavior
Some systems simply have no rules in physics that can describe them well. Think of human attention, trust, or preferences. In such cases, behavior must be learned from data.
In website optimization, for example, ML models can learn how users react to layout changes, rankings, or pricing decisions. This learned behavior is then given to the optimizer, which adjusts the website while respecting multiple other constraints: revenue targets, fairness requirements, budgets, and contracts.
Where this pattern works - and where it breaks
This pattern is particularly powerful when:
Human behavior must be observed
Sufficient data is available to learn stable behavioral responses
Decisions must satisfy non-negotiable constraints (otherwise, an occasional hallucination would be acceptable, but optimization guarantees no hallucinations)
It breaks when learned behavior is treated as static truth, and its drift over time is forgotten.
A Match made in Heaven
Machine learning is a powerful tool for describing reality from data. Optimization is a strong tool for choosing actions under constraints.
They work better together when each is used for what it is best at, and when both uncertainty and assumptions are dealt with honestly rather than ignored. Once you find the pattern that your problem fits into, implementation often becomes relatively straightforward.
If you want to take these ideas further, I have put together a practical framework for you here. Or just reach out, I am always happy to talk optimization.
 | A guest post by
|