
From a Single Server to Global Scale
The evolution of a web application architecture when going from serving hundreds to millions of users.

Hi Friends,
Welcome to the 139th edition of the Polymathic Engineer.
This week, we will look at the typical evolution stages of a web application when passing from serving a few hundred to millions users.
The outline will be as follows:
The Scaling Journey
Single Server Setup
Separating Concerns
Scaling the Application Layer
Primary-Replica Architecture
The Cache Layer
Sharding
Handling Massive Static Content
The Microservices Evolution
GeoDNS and Edge Servers
Project-based learning is the best way to develop solid technical skills. CodeCrafters is an excellent platform for practicing exciting projects, such as building your version of Redis, Kafka, DNS server, SQLite, or Git from scratch.
Sign up, and become a better software engineer.
The Scaling Journey
Suppose you're building your first web application. It could be an e-commerce site, a social platform, or a productivity tool. You pay for a single server, put your code on it, and then you launch the app. For the first hundred people, everything works great.
But what if your application takes off, and traffic grows from hundreds to thousands to hundreds of thousands of users?
Every successful application follows a similar path. It starts simple, hits bottlenecks, evolves to solve them, then hits new bottlenecks. Each stage brings its challenges and requires different solutions.
You can't skip stages. It doesn’t make sense to start with the architecture that serves millions of users when you have hundreds. Not only would it be costly and complex, but you'd also be solving problems you don't have yet. Each stage addresses specific problems that emerge as your user base grows.
If an app works for a thousand users, it might not work for ten thousand. In the same way, the architecture that serves a hundred thousand users becomes too complex and expensive for ten million. The beauty is in the progression. Each stage builds on the previous one, adding just enough complexity to solve the current bottleneck without over-engineering for problems you don't have yet.
The scaling path we discuss this week represents how most startups built applications until about a few years ago. Back then, you started with a single server and gradually added complexity as you grew.
Today, with cloud computing and serverless technologies, the game has changed. You can start with an architecture that can handle thousands of people without spending a lot of money up front. Services like AWS Lambda, managed databases, and CDNs let you skip over a few stages of the evolution.
But the traditional path still matters because it teaches you the basic concepts. When you understand why each architectural pattern exists and what problems it solves, you make better decisions also in the cloud-native world.
Single Server Setup
Let's start with the simplest possible setup: run everything on one machine. With this configuration, your entire app runs on a single server accessible over the internet. The server handles all of your web app's code, holds your database, and serves static files like images and CSS from its own hard disk.
People who want to visit your website must first connect to a DNS server to obtain the IP address. Once they have that, they send all of the requests directly to your machine.
A single-server configuration works surprisingly well in many use cases and is perfect for simple company websites, small e-commerce stores, or blogs. Depending on how complex your app is, you could probably serve even thousands of users without severe issues. Many small projects start this way, and some never need to evolve beyond it.

However, as your application and your user base grow, you'll start hitting limits. Your server's CPU usage stays high even during off-peak hours. Your database queries get slower, especially for common operations. Users complain about slow page loads or timeouts.
When your single server starts struggling, the tempting solution is to make it bigger and more powerful. This is called vertical scaling, and while it can buy you time, it's not a long-term solution.
You can upgrade from 8GB of RAM to 32GB or 128GB. You can add more CPU cores, faster disks, and network cards. For a while, this works great and doesn't require any code changes.
But vertical scaling has limits. At some point, you can't buy more powerful hardware, or the cost becomes ridiculous. A server with 128GB of RAM costs $3K, but doubling that to 256GB might cost $18K.
Even if your server could handle the load forever, running everything on one machine has a serious operational problem: there's no backup plan. If your server goes down, your entire application becomes unavailable. The downtime could last anywhere from minutes to hours, depending on the issue and how quickly it can be fixed. This kind of downtime is unacceptable for a business that relies on its web application.
That's why the real answer is to start spreading your system across multiple machines.
Separating Concerns
The logical first step when using more than one server is to separate different parts of your system onto different machines. This is a simple form of horizontal scaling.
One clear way to split is to put your database on its own server. Most of the time, the database workload needs different resources than the web server workload. Databases require a lot of memory and disk I/O, whereas web servers demand more CPU power to process requests.
By separating them, you can tune each server for its specific job. Your web server can have fast CPUs and moderate memory. Your database server can have tons of memory and fast disks. Neither server wastes resources on things it doesn't need.
If your application serves a lot of static content (images, videos…), you might also want a dedicated file server optimized for storage and network throughput.
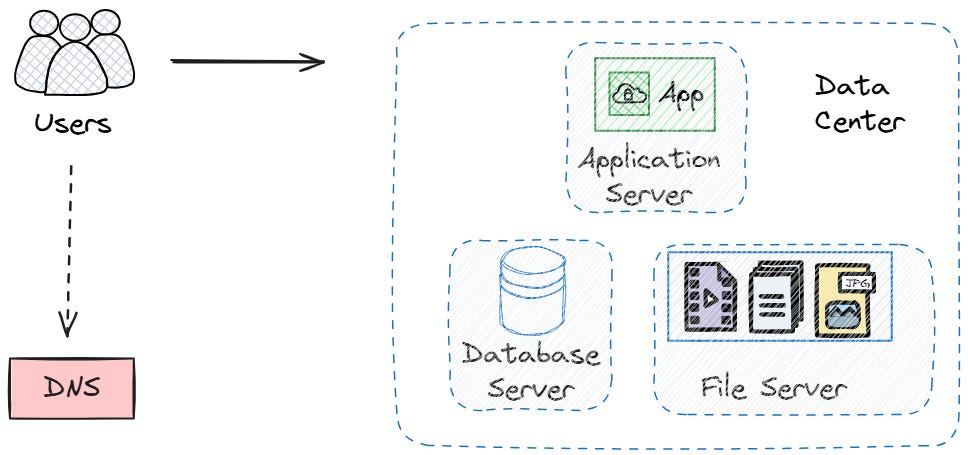
One more option at this point is functional partitioning. Instead of separating services, you can split your application by feature or user type. You could put your main app on one server and your admin dashboard on another, for instance.
This approach works well if different parts of your app are used in different ways or need different levels of performance. There is a chance that your admin dashboard needs to be very reliable but it is not very busy. On the other side, your main app may need to be able to handle sudden traffic jumps, but it can tolerate problems now and then.
While separating concerns solves some problems, it doesn't take you that far. You still have potential single points of failure. If your single web server gets too busy, moving the database to another machine won't help. You need multiple servers to share the load. Similarly, if your database server can't keep up with queries, having a dedicated file server doesn't solve that problem.
Scaling the Application Layer
When a single web server can't handle all the traffic, it's time to add multiple servers.
The solution is straightforward: put a load balancer between your users and your web servers. All responses come in through the load balancer, which then sends them to different application servers.
Round robin is the most common way to split up the traffic. It sends requests to the servers in order, from server 1 to server 2 to server 3 to server 1, and this keeps the load even. An alternative is to have sticky sessions and redirect all requests from the same user always to the same server.
While sticky sessions might seem to have a logic, they cause problems. There may be more busy users on some servers than on others, and if a server crashes, everyone who was logged in gets logged out.
To use round-robin distribution, you need stateless servers that don't keep any state, so that subsequent requests to a server do not depend on something being stored on that server from a previous request. This means that servers don't store user session data locally, but in a shared location like your database or a dedicated session store.
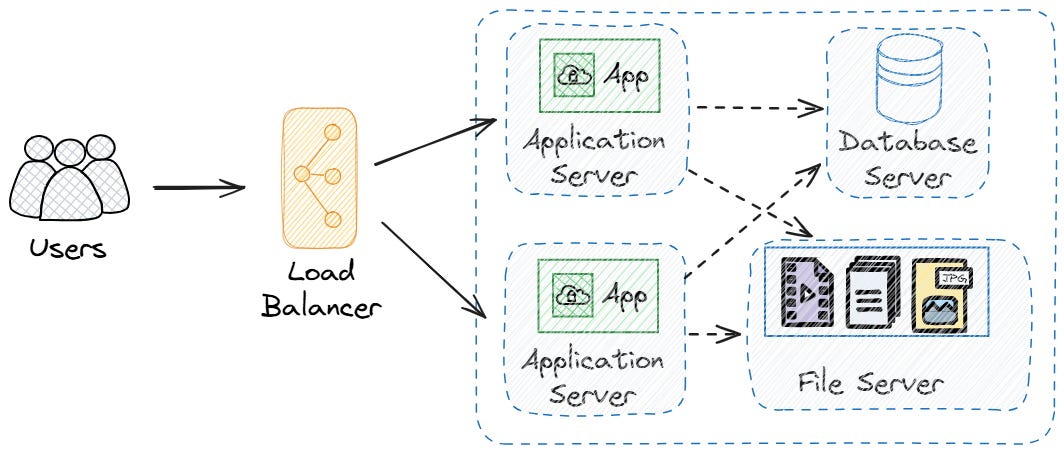
When an application server gets a request, it fetches the user's data from the shared store, processes it, and, if necessary, updates it. Every server can handle any request because all the information it needs is in the shared store.
This method makes things more resilient. Users won't lose their sessions if one server goes down because the data is saved separately. The load balancer automatically stops sending requests to a server that isn't working and distributes them among the others.
With multiple application servers behind a load balancer, you can handle much more traffic. You can keep adding servers as your user base grows, and the load balancer will distribute requests among all of them.
But at some point, you'll run into another problem. There is only one database that all of your application services are trying to read from and write to. That's when you need to start thinking about database scaling strategies.
Primary-Replica Architecture
Adding more web servers doesn't help when too many requests hit the same database at the same time.
The problem usually shows up as slower query response times, especially during peak usage. Users start to wait longer when they use features that use a lot of data or try to load their profiles.