Designing a URL Shortener
How to answer this popular system design question: from a simple concept to a scalable system.

Hi Friends,
Welcome to the 133rd issue of the Polymathic Engineer newsletter. Designing a URL Shortener is one of the most popular and classic system design interview questions, and there is a reason for that.
The question has a non-trivial algorithmic part related to URL generation, and covers a lot of ground when it comes to how to scale a system, provide high availability, and think about a data model.
In this issue, we will discuss how to answer this question in a systematic, structured, and pragmatic way. The outline is as follows:
Understanding the Problem
Capacity Planning
System Architecture
The Core Challenge: Generating Short URLs
Database Design and Storage
Caching for Performance
Analytics Service Design
Project-based learning is the best way to develop technical skills. CodeCrafters is an excellent platform for practicing exciting projects, such as building your version of Redis, Kafka, DNS server, SQLite, or Git from scratch.
Sign up, and become a better software engineer.
Understanding the Problem
A URL shortener is a service that turns long, hard-to-use URLs into short, easy-to-use ones. When someone clicks on the short URL, they’ll be taken straight to the original site. TinyURL and Bitly are all well-known examples.
Consider this real-world scenario: you want to share a link to an article, but the URL looks like this:
https://www.example.com/blogs?id=1pzWy3zLWkCXty4Yf3euAuwNJjheFOtN2d8j4001spk&source=referral&redirect=92532049&toggle=true&events=event2943v6Not only is this URL difficult to read and share, but it might not even fit in character-limited social platforms like Bluesky. A URL shortener transforms it into something clean like:
https://short.ly/abc123Beyond aesthetics, URL shorteners also do a few very important things. For example, they can support custom domains or track analytics to see how many people click on your links, where they come from, and when they click.
When designing a URL shortener that is able to handle millions of users, we need to consider both functional and non-functional requirements:
Functional Requirements:
Accept a long URL and return a unique short URL
Redirect users from short URLs to original URLs
Support custom short URLs (when available)
Provide basic analytics on link usage
Allow URLs to expire after a set time
Non-functional Requirements:
High availability: The service should be available 99.9% of the time
Low latency: Redirections should happen in under 100ms
Scalability: Handle 100 million daily active users
Durability: Short URLs shouldn't be lost for 5 years
Capacity Planning
Before thinking about a possible design, we need to understand what we're dealing with in terms of scale. Here is where some back-of-the-envelope calculation comes into play. If we assume 100 million daily active users, we can estimate:
Write operations: If each user creates three short URLs per month on average, that's about 115 new URLs created per second (300M URLs / (30 days * 86400 sec)
Read operations: URL shorteners are heavily read-focused. With a 100:1 read-to-write ratio, we're looking at about 11,500 redirections per second on average
Storage: Each URL record is at least 500 bytes (urlIdD, creationDate, userID, longURL). Over 5 years, this means we'd need about 10TB of storage
Bandwidth: Peak traffic could reach several MB/s for serving redirections
This scale means we can't rely on a single server or a simple database setup. We need a distributed system that can handle traffic spikes, store data reliably, and provide fast responses globally.
System Architecture Overview
A URL shortener has two main jobs: to shorten URLs and redirect users to different pages. At a very high level, a system supporting these operations consists of multiple components working together.
The API Layer handles incoming requests from users and applications. It includes Web servers that process HTTP requests, load balancers to distribute traffic evenly, and rate limiters to prevent abuse.
The Application Services carry out the business logic components. For example, the URL shortening service creates short URLs, the redirection service looks up original URLs, and the analytics service keeps track of usage.
The Data Layer is in charge of storing information. We need a primary database for URL maps, a cache layer for frequently accessed URLs, and an analytics database to track clicks and measure performance.
The process of creating a short URL (the write path) begins with the user submitting a long URL through the API. The system then comes up with a unique short identifier and encodes it for readability. After the mapping is stored in the database, the system gives the user the short URL. This could be how the REST API for that service looks:
POST /shorten
{
"long_url": "https://example.com/very/long/path",
"custom_alias": "mylink" (optional),
"expires_at": "2024-12-31" (optional)
}
Response:
{
"short_url": "https://short.ly/abc123",
"created_at": "2024-01-15T10:30:00Z"
}
The process of redirecting a short URL to the original one (the read path) begins with the user clicking a short URL. The system retrieves the identifier from the URL and checks the cache for the corresponding mapping. If the answer is not already in the cache, it asks the database for it and adds it to the cache. Finally, it redirects the user back to the original URL. This could be how the REST API for that service looks:
GET /abc123
Response:
HTTP 301 Moved Permanently
Location: https://example.com/very/long/pathThe Core Challenge: Generating Short URLs
The most important thing about any URL shortener is how it makes new short URLs. At first, this may seem easy, but it gets much harder when you need to make millions of unique identifiers that are readable, don't collide, and can't be predicted.
Before diving into solutions, let's understand what makes a good short URL:
Collision-free: for the system to work, it's absolutely critical that no two different long URLs should ever get the same short URL.
Readable: The short URL should only contain alphanumeric characters.
Non-predictable: It shouldn't be possible to guess the following short URL based on previous ones. This prevents people from scanning your entire database.
Short length: Ideally, seven characters or fewer to keep URLs truly "short."
The encoding method is the first thing that needs to be chosen. Encoding changes the form of data from one type to another, and it's necessary to improve the readability of the short URL and make it less error-prone. A lot of binary-to-text encodings could be used. Base32 uses an alphabet of 32 digits (A–V, 0–9) to represent different sets of 5 bits, while Base64 uses an alphabet of 64 digits (a-z, A-Z, 0–9, +,/) to represent different sets of 6 bits.
To meet the scalability requirements, we need an encoding that can create 18 billion unique identifiers (300 million URLs per month times 12 months times 5 years). If we assume the URLs are 7-character long, the Base32 format can hold about 34 billion IDs (32ˆ7), which is enough, but it doesn't represent lowercase characters. Base64 can hold about 4 trillion (64ˆ7) IDs and satisfy all the system's needs. Another good option is the Base58 encoding, which avoids non-distinguishable characters such as capital O and 0, or capital I and lowercase L.
Now that we discussed encoding formats, let's look at three different ways to generate these short URLs and see why some work better than others.
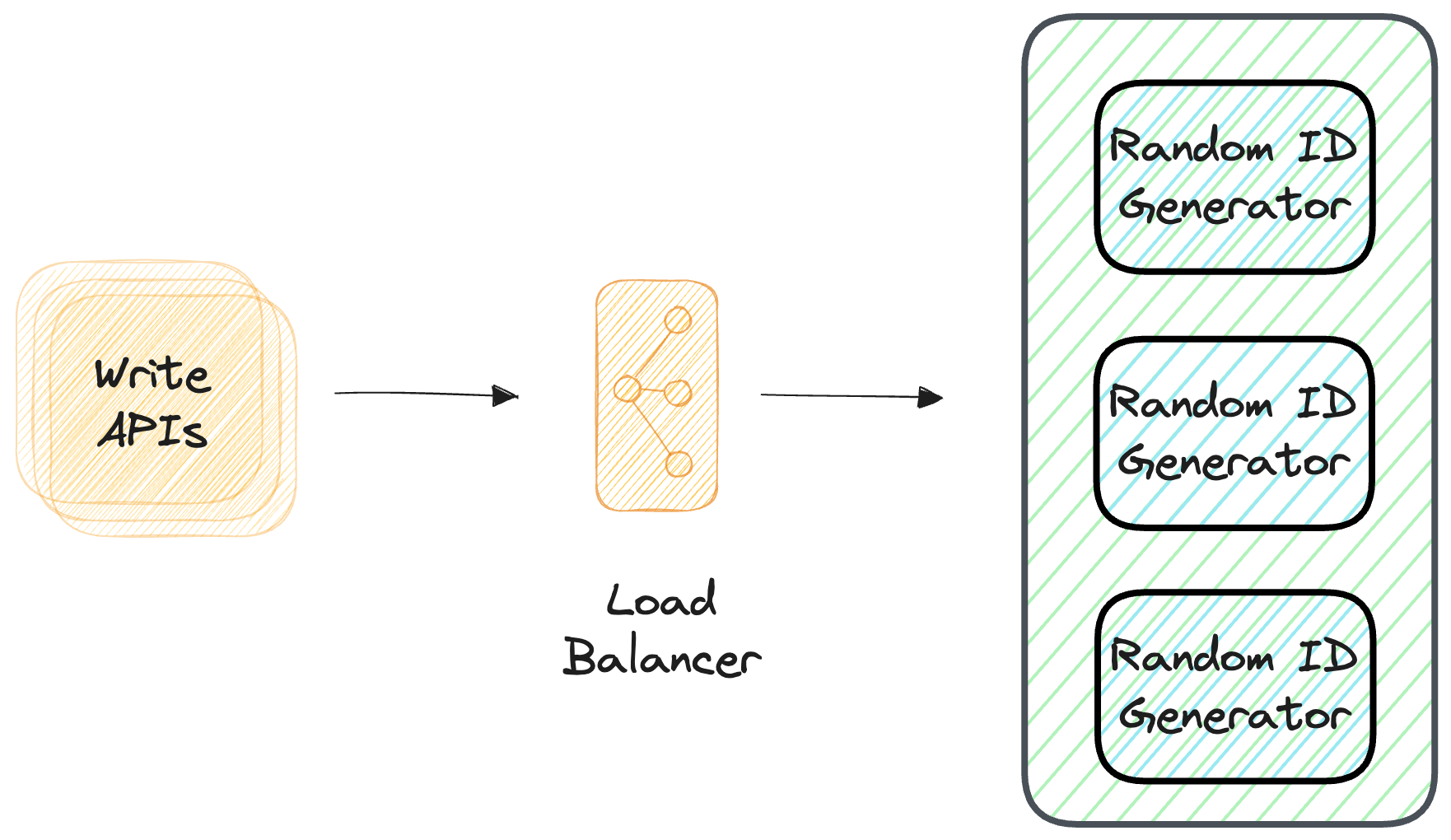
The easiest idea that comes to mind is generating random IDs. You could use UUIDs or pick random characters and hope for the best. However, this doesn't work on scale. With millions of URLs, you'll start getting collisions frequently, which will break the 1:1 mapping requirement. To fix this, you'd have to check each time you make a new URL if that random ID already exists, which becomes a performance bottleneck. Also, multiple servers generating random IDs would need to coordinate to avoid conflicts.