
Chain Replication
A different way to do replication in distributed systems that gives you high availability and throughput.

Hi Friends,
Welcome to the 142nd issue of the Polymathic Engineer newsletter.
When building distributed systems, one of the most complex challenges is making storage systems that can handle failures well while still providing strong consistency. If you must handle thousands of requests per second across multiple servers, it's easy to see how availability, speed, and consistency are often at odds with one another.
The traditional ways in which replication has been done are based on uneasy trade-offs. Leader-based protocols, such as Raft, offer strong consistency, but they slow things down at the leader. Quorum-based approaches, on the other hand, often give up availability for consistency.
Instead of having a single leader or complicated quorum rules, another option is to set up servers in a simple chain where each server has a clear job to do. The end result is a protocol that can easily deal with failures, has high throughput for read operations, and keeps strong consistency guarantees.
In this article, we'll look at how chain replication works, how well it works, and why it might be the right choice. When you understand chain replication, you'll have another useful tool for building distributed systems, such as a storage service, a cache layer, or any other system that needs to replicate data reliably.
The outline will be as follows:
Chain Replication Fundamentals
How Chain Replication Works
Fault Tolerance and Failure Handling
Adding New Servers to the Chain
Performance Characteristics
Project-based learning is the best way to develop technical skills. CodeCrafters is an excellent platform for practicing exciting projects, such as building your version of Redis, Kafka, DNS server, SQLite, or Git from scratch.
Sign up, and become a better software engineer.
Chain Replication Fundamentals
Chain replication is based on a simple yet powerful concept: set up your servers in a straight line, like links in a chain. The method works well because each server in this chain has a specific role. Overall, there are three types of servers:
Head: The first server in the chain. It receives all write requests from clients and starts processing them.
Middle servers: These servers sit between the head and tail and forward updates along the chain.
Tail: The last server in the chain. It takes care of all read requests and makes sure that writes are completed.
When a client wants to update data, it sends the write request to the head. The head processes the update and forwards it to the next server in the chain. After that, each server in the chain applies the update and passes it forward. When the update reaches the tail, it sends an acknowledgment back through the chain. Once the head receives the acknowledgment, it informs the client that the write succeeded.
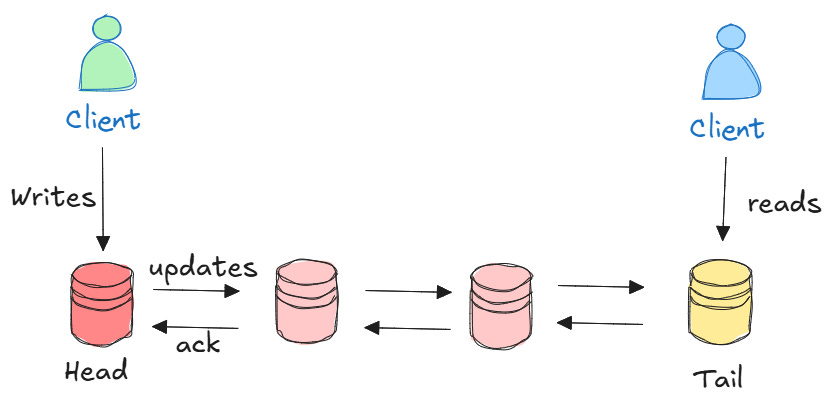
Reading data is much more straightforward. All read requests go directly to the tail. Since the tail is the last server to receive any updates and has the most up-to-date data, clients always get consistent results.
The beauty of this approach is its simplicity. By having all reads directed to one place (the tail) and all writes initiated from another (the head), you avoid all the coordination overhead that slows down other replication methods.
The tail acts as a natural synchronization point. Since every update must pass through it, and all reads come from it, you get strong consistency without tricky coordination protocols.
How Chain Replication Works
To get a better intuition of how chain replication works, let's have a look at a practical example where a chain has three servers: Head → Middle → Tail.
When a client wants to write new data, the process follows these steps:
The client sends an update request to the head server
The head applies the update to its local copy of the data
The head sends the updated data to Middle
Middle applies the update and forwards it to the tail
The tail applies the update and sends an acknowledgment back to Middle
Middle forwards the acknowledgment to the head
The head tells the client the write was successful
As you can see, this workflow ensures that every server in the chain has the same data before the client gets confirmation.
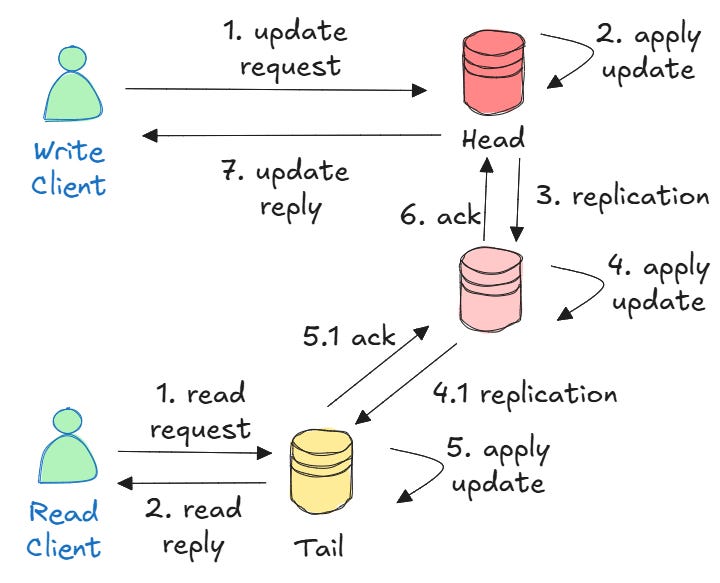
When a client wants to read data, the process is much simpler: