
Caching in Distributed Systems - Part II
An overview of more advanced cache concepts: read and write strategies, replacement policies, invalidation, and TTL.

Hi Friends,
Welcome to the 144th issue of the Polymathic Engineer newsletter.
This week, we will continue our deep dive on caching in distributed systems. While in the last issue we focused mainly on performance and deployment strategies, this time we will discuss read/write strategies and all what is related to cache management. The outline will be as follows:
Cache Strategies and Patterns
Read Strategies
Write Strategies
Strategy Combinations
Cache Management
Cache Replacement Policies
Cache Invalidation and TTL
Project-based learning is the best way to develop solid technical skills. CodeCrafters is an excellent platform for practicing exciting projects, such as building your version of Redis, Kafka, DNS server, SQLite, or Git from scratch.
Sign up, and become a better software engineer.
Cache Strategies and Patterns
Once you set up your cache infrastructure, you need to decide how your application will interact with it. The strategy you choose determines how data is moved between your application, the cache, and the underlying backing store, such as a database or service. This choice has a significant effect on both performance and data consistency.
There are two main types of strategies: read strategies control how new data is added to the cache, and write strategies determine how data updates are processed. These techniques are typically used together in production systems to create a complete caching solution.
Read Strategies
When there is a cache miss, you need to decide whether the cache is passive or active. This means that if your app tries to get a value from the cache but this isn’t present or has expired, the caching strategy decides whether the app or the cache should get the value from the underlying store. As always, different caching solutions offer distinct advantages and disadvantages in terms of latency and complexity. Let’s get started.
Cache-Aside
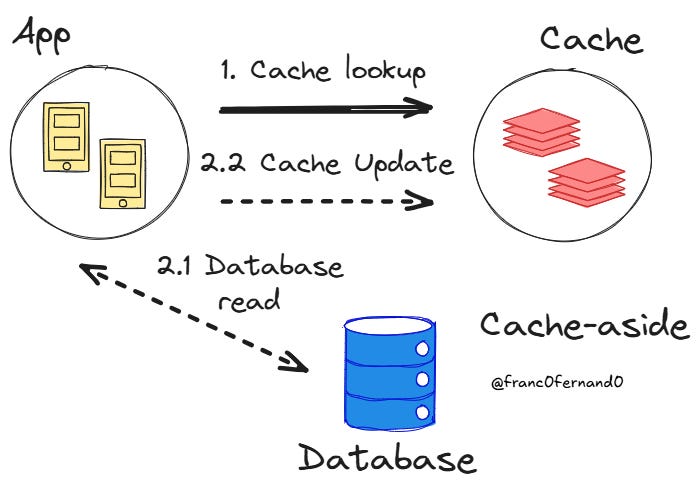
Cache-aside, which is also called lazy loading, is the most popular method and likely the first one you will come across. Here, your application code directly manages both the cache and the database, and the cache is a passive component when a cache miss occurs.
When the application needs data, it first checks the cache. If the data is present, the cache returns it immediately. Otherwise, the app fetches the data from the database, stores it in the cache, and then returns it to the user.
For example, suppose you are caching information about users and using their ID as the search key. If the key exists, the cache returns the value associated with it, which the application can use. If not, the application then runs a query based on the user ID to get information about the person from the database.
The database then sends back information about the person, which is then changed into a format that can be stored in the cache. Finally, the cache is updated with the user ID as the cache key and the information as the value. A typical way to perform this type of caching is to transform the user information returned from the database into JSON and store that in the cache.
This strategy works well for read-heavy workloads, and it is straightforward to set up. You don’t have to worry about filling up the cache with data that might never be used, as it is only loaded when requested. What gets cached and for how long is entirely up to the application.
Developers like cache-aside because it’s simple to set up a cache server, such as Redis, and use it to store database queries and service replies. The cache server doesn’t need to know what database you use or how the results are mapped to your cache.
However, with cache-aside, your application code must handle all cache management and data transformation. This might be tricky if you need to make sure that the data is consistent and up to date. You have to deal with cache misses and make sure that the cache and database both have the same data.
If multiple requests are made for the same key at the same time, your application code must also coordinate how it handles concurrent cache misses. If you don’t, you might perform multiple database accesses and cache updates, which could result in different cache values being returned on subsequent queries.
Cache-aside can also bring a high tail latency because some cache lookups experience the full database read delay on a cache miss. Even in the case of a high cache hit ratio, the requests that do miss the cache are only as fast as database access.
Read-Through
With read-through caching, the cache is between your application and the database, serving as the single point of contact for all read operations. When your application requests data, it only talks to the cache, and the cache is an active component in the event of a cache miss. If the cache has the data, it returns it immediately. If it hasn’t, the cache gets the data from the database, stores it, and sends it back to the app.
A cache miss is invisible to the application because the cache always returns a value, even if it does not exist in the cache and must be retrieved from the database.
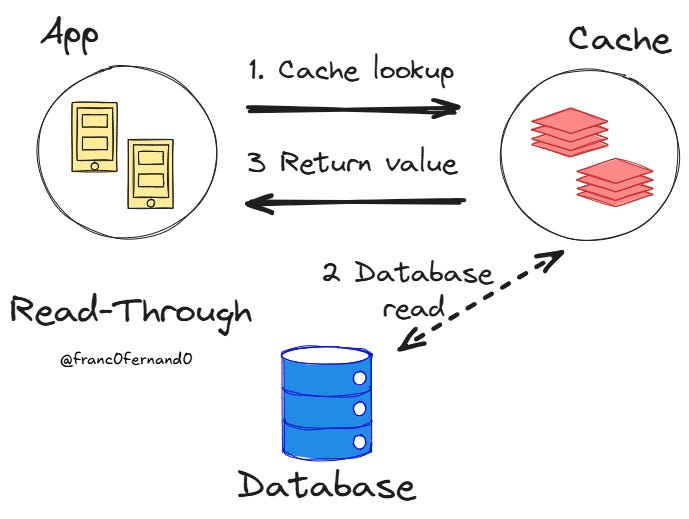
This approach simplifies the application code because it only needs to interact with a single system. Since the cache handles both updates and the retrieval of data from the database, it can provide the application with transactional guarantees and ensure that the cached data and external data stores are in sync. In the same way, a read-through cache can ensure consistency for concurrent cache misses.
The downside is that the cache becomes a critical dependency. If the cache fails, your application can’t access any data, even data that exists in the database. You also don’t have as much control over how caching works because the cache system handles the database interactions.
Read-through caching is also harder to set up because the cache needs to be able to read from the main store and change the database results into a format that can be cached. For example, if the database is an SQL server, you need to convert the query results into a JSON or similar format to store the results in the cache. The cache is, therefore, more coupled with your application logic because it needs to know more about your data model and formats.
Write Strategies
Cache-aside and read-through caching are strategies for reading, but sometimes you also want the cache to allow writes. Therefore, the cache gives the application a way to change the value of a key when this happens.
In cache-aside caching, the app is the only one that talks to the backing store, so it is the application that changes the cache. On the other side, with read-through caching, you can handle writes in two different ways: write-through and write-behind caching.
Write-Around
Write-around is the most straightforward write strategy and works well with cache-aside for reads. When data needs to be updated, the application writes straight to the database, skipping the cache totally.