
Caching in Distributed Systems - Part I
From theory to production: cache performance, architecture, and deployment strategies.

Hi Friends,
Welcome to the 143rd issue of the Polymathic Engineer newsletter.
This week, we start a small series of in-depth articles regarding caching in distributed systems. A few of you who have been reading my work since the beginning might remember that we talked about caching in one of the first issues. Now I think it’s time to write about it again and cover every possible detail.
The outline of this week will be the following:
What is Caching and Why Does it Matter
Caching Use Cases
Understanding Cache Performance
Cache vs. Storage Systems
Cache Deployment Strategies
Distributed Caching Architecture
Project-based learning is the best way to develop solid technical skills. CodeCrafters is an excellent platform for practicing exciting projects, such as building your version of Redis, Kafka, DNS server, SQLite, or Git from scratch.
Sign up, and become a better software engineer.
What is Caching and Why Does it Matter
A fact about modern systems is that speed matters a lot. For example, Amazon found that every 100ms that the time it took for a page to load cost them 1% in sales. Google, in the same way, found that a 0.5-second delay in loading a search result page resulted in a 20% drop in traffic. These results show that speed improvements can have a huge impact on the user experience and, by extension, on the success of a business.
An effective way to enhance a system's performance is to utilize caching. Generally speaking, a cache is a piece of hardware or software that stores data to be served more quickly than in its original location when needed again. The information in the cache could be the result of a calculation done earlier or a copy of data stored elsewhere.
Let's look at a concrete example to understand how this works. Consider a typical client-server application that doesn't use caching. When a client makes a request, the server retrieves data from the database and sends it back. This process works fine for small loads, but when there is a lot of traffic, getting data from storage gets slow and can cause bottlenecks.
Adding a cache to the system completely changes the game. When data is requested, the service first checks the cache. If the data is present, it is quickly returned to the client. If the data isn't in the cache, the service retrieves it from the original storage, caches it for later use, and then sends a response to the client.
The speed difference can be huge because caches store data in memory using data structures optimized for fast access, and reading from disk is orders of magnitude slower than reading from memory.
Caching Use Cases
Although our previous example was about caching at the application level, it is crucial to recognize that computers and software systems in general use caching a lot. Here is a list of use cases, it's worth knowing about:
Hardware Caches. Modern computers have more than one level of cache to help the CPU quickly get frequently used data. The L1 cache is right on the CPU chip and is the smallest and fastest. L2 and L3 caches are larger and a bit slower than L1, but they are still significantly faster than main memory. This hierarchy makes sure that the most frequently used data is available quickly. Another type of cache on your computer is the Translation Lookaside Buffer (TLB), which is part of the Memory Management Unit (MMU). Since the TLB keeps track of the most recent address translations, it allows a faster conversion from virtual to physical memory addresses.
Operating System Caches. The operating system employs a page cache in main memory to speed up the whole system. When you read a file, the operating system (OS) doesn't just load the bytes you asked for; it loads whole pages of data because it assumes you'll need the data around the bytes soon. This page cache stores data pages that are used more often, which considerably reduces the number of times the disk needs to be accessed.
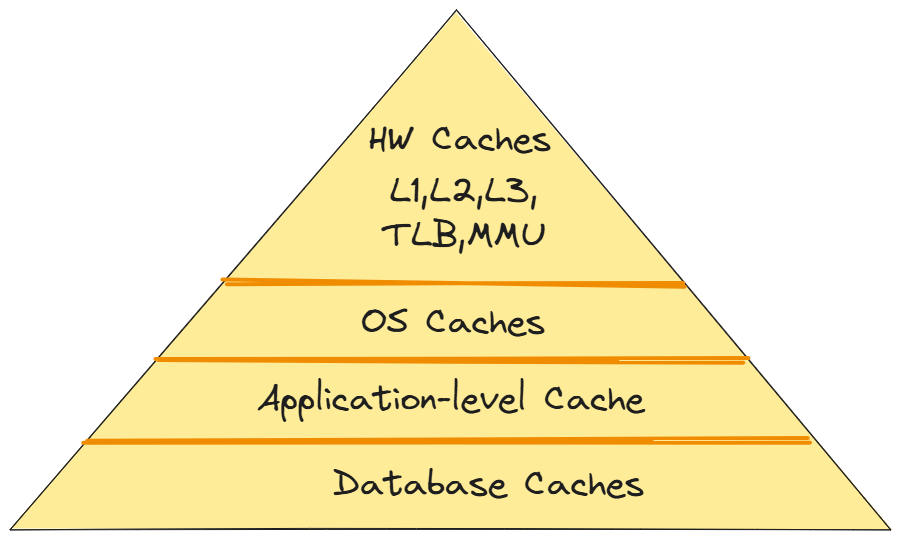
Application-Level Caches. This is where most developers work with caching. For example, browsers store website pictures, stylesheets, and documents in caches to make pages load faster and browsing more smoothly. When you revisit a website, many of the resources are already stored locally. Another type of application-level caching is Content Delivery Networks (CDNs). CDNs are networks of servers that are geographically distributed and store static items like photos, movies, and CSS files. When you ask for a file, the CDN sends it from the server that is closest to you. This makes load times much faster.
Database Caches. Databases utilize many types of internal caches to speed things up. The buffer cache stores frequently used data pages in memory. Query caches keep the results of big searches. Metadata caches make it easy to get information about searches and table structures. All of these caches work together to make it faster to read from files and run queries.
In this article, we will primarily focus on caching in distributed systems, exploring its core principles, techniques, applications, and related issues.
Understanding Cache Performance
Two primary factors determine how effective a cache is: cache hits and cache misses. When requested data is available in the cache, it's called a cache hit. When the data isn't found and must be retrieved from an origin source, like a data store, it's a cache miss.
Since it's much faster to access data from cache than from the origin, systems operate more efficiently when there are more cache hits. The best metric for determining how well the cache is working is the cache hit ratio, which is calculated by dividing the number of cache hits by the total number of cache requests. The higher the ratio, the better the overall performance.
There are three primary factors that influence the hit ratio:
Size of the key space. The only way to locate an item in the cache is by exactly matching its key. So, the fewer possible cache keys, the more efficient the cache will be.
Cache and size of the items. The number of objects you can store in the cache depends on their average size and the size of the cache. When the cache is full, you must replace older items before adding new ones. But this reduces the hit ratio, as they must be removed even if they might satisfy future requests. Therefore, the more items you can fit into the cache, the better your cache hit ratio will be.
Longevity. In many cases, you can cache objects for a predefined time, known as Time to Live (TTL). In other cases, you may be unable to risk serving stale data, and you must invalidate cached objects. Generally, the longer you can cache your items, the higher the chance of reusing them.
Most use cases that are good for caching have a high ratio of reads to writes. This is because cached items can be created once and stored for an extended period before they expire or become invalid. On the other hand, use cases that frequently change data could render the cache useless because items may become invalid before being used again.
The data access patterns in most applications follow the Pareto distribution. A small amount of data (around 20%) typically accounts for a large portion of traffic (around 80%). By caching frequently accessed data, a cache can intercept most requests, which significantly reduces the load on the origin and boosts overall throughput.
However, caching comes with trade-offs. It requires additional resources and makes the design of your system more complicated. In distributed environments, it can be hard to keep data consistent, and you need to consider various edge cases. But when implemented correctly, the performance benefits usually far outweigh these costs.
Understanding these fundamentals is crucial because, as we will see in the following sections, successful caching isn't just about placing a cache in front of the origin; it's also about selecting the right strategies, managing the inevitable complexity, and designing for how production systems actually operate.