
A Practical Guide to Types of Machine Learning
Understanding supervised, unsupervised, and reinforcement learning. How to choose the right approach for your problem.

Hi Friends,
Welcome to the 159th issue of the Polymathic Engineer newsletter.
As you know, machine learning is everywhere. It powers the movie recommendations you see on Netflix, filters spam from your inbox, enables self-driving cars to navigate city streets, and can even help doctors diagnose diseases. However, behind all these applications lies a fundamental question: what type of machine learning should you use?
There are multiple ways to classify machine learning systems. The most common is based on the type of supervision they receive during training. However, you can also categorize them by whether they learn incrementally or all at once, or by how they generalize what they have learned from training data to new examples.
Understanding these distinctions is important because choosing the wrong approach wastes time and resources. You cannot build a spam detector system without labeled spam examples. In the same way, you can’t group customers into segments if you have already decided what those segments should be. Determining which machine learning method is right for the job is the first step to building something that works.
In this issue, we will have a look at the different types of machine learning and see the use cases they fit. The outline is as follows:
Labeled vs Unlabeled Data: The Foundation
Supervised Learning: Predicting Labels
Unsupervised Learning: Finding Hidden Patterns
Reinforcement Learning: Learning Through Interaction
Beyond the Big Three: Other Ways to Classify ML Systems
Project-based learning is the best way to develop technical skills. CodeCrafters is an excellent platform for tackling exciting projects, such as building your own Redis, Kafka, a DNS server, SQLite, or Git from scratch. Sign up, and become a better software engineer.
Labeled vs Unlabeled Data: The Foundation
Before diving into the different types of machine learning, we need to understand the raw material that powers them all: data. In fact, machine learning is just the field that studies how to teach computers to learn from data. The examples that the system uses to learn are called the training set, while the part of the system that learn and generates predictions is known as the model.
Data is just information put together in a structured way. If you have a table with rows and columns, you have data. Each row represents a single data point, and each column represents a feature, which is a property or trait that describes that data point.
For example, in a dataset of houses, some features include size, number of bedrooms, distance to the nearest school, and the local area crime rate. In an email dataset, the features could be the sender, the subject, the body text, or the number of attachments.
But here is where things start to get interesting. Some features stand out to us, and we refer to them as “labels.” A label is a feature we want to predict. It’s the answer we are looking for based on all the other features. The important thing is that what counts as a label depends entirely on the problem we’re trying to solve. If we’re predicting house prices, the price is the label; if we want to detect spam emails, the label is spam/not-spam classification; if we’re estimating how long it will take for a patient to recover, that time is the label.
The goal of a machine learning model is to analyze the features and produce the most accurate possible prediction of a label. This brings us to a fundamental distinction:
Labeled data comes with the answers already filled in. We know the house prices, we know which emails are spam, and we see the patient outcomes.
Unlabeled data has no such answers. We have all the features, but no target to predict.
For example, a set of emails marked as “spam” or “not spam” is labeled data. A set of emails without such tags is unlabeled.
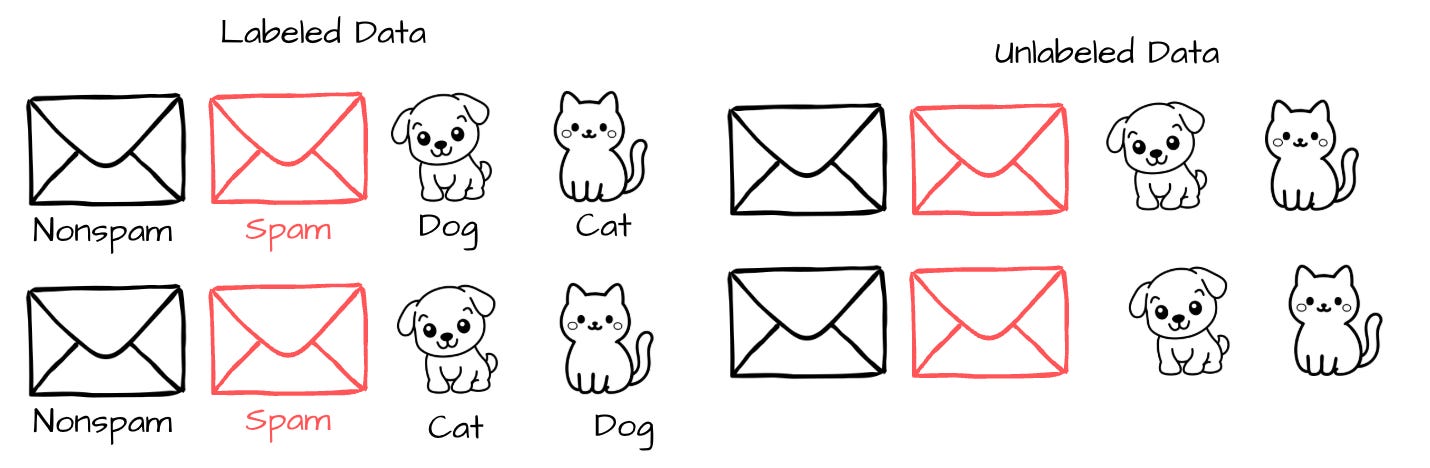
Why does this matter? Because the type of data you have determines which machine learning approach you can use. Labeled data enables supervised learning, where the model learns from examples with known correct answers. When you give a model unlabeled data, it has to learn on its own, without being told what to look for. This is called unsupervised learning. This distinction is the foundation for everything that follows.
Supervised Learning: Predicting Labels
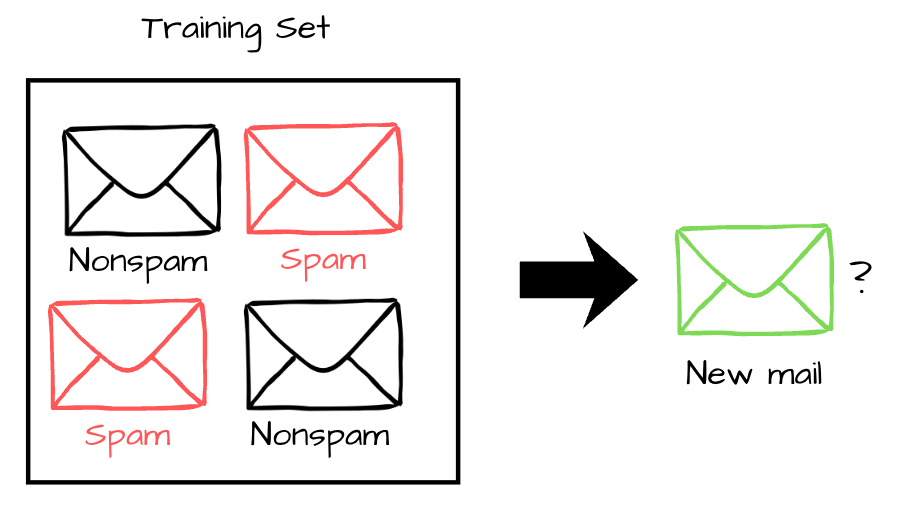
Supervised learning is the most widely used type of machine learning. It’s what makes picture recognition, spam filters, recommendation systems, and a massive number of other applications we use every day possible. The defining characteristic is simple: the training data includes the answers we want the model to learn.
In supervised learning, the model follows a remember-formulate-predict framework. The first thing it does is load the training dataset and memorize the examples. Then it comes up with rules or patterns that link the labels to the features. Lastly, when a new piece of data comes in, the model uses those rules to guess what the label will be.
For example, a spam filtering system looks at thousands of emails that have already been marked as spam or not spam to figure out what patterns make them different. It then uses those patterns to classify new incoming emails.
Supervised learning problems fall into two categories, based on what we want to guess.
Regression models predict numerical values. The output is a number that can take on many possible values. An example of a regression problem is predicting how much a house will cost based on its size and location. Other examples might be estimating how long a customer will stay on a website or forecasting stock prices. The most used regression method is linear regression, which fits a line (or a higher-dimensional surface) to the data. Other popular approaches include decision trees and ensemble methods like random forests and gradient boosting.
Classification models predict categories. There are only a limited number of possible states for the output. Finding spam is like dividing emails into two groups: those that are spam and those that are not. Image recognition is also classification. Given an image, the model tells you whether it contains a cat, a dog, a car, or another category. Logic regression, decision trees, support vector machines, naive Bayes, and neural networks are all common classification methods.
The line between regression and classification is not always rigid. Some algorithms can do both things with only small changes. For example, logistic regression produces numeric values representing the probability of belonging to a given category, making it commonly used for classification.
Supervised learning can be very accurate when there are many well-labeled examples. Labels, on the other hand, can be pricey. Someone has to mark those emails as spam by hand, put those pictures into the right category, or write down the actual prices of the homes for sale. Supervised learning might not work in domains where marking is hard or expensive, at least not without help from other methods.
This is where semi-supervised learning comes in. There are algorithms that can work with data that is only partly labeled, meaning that many cases aren’t labeled and only a few are. Photo-hosting services such as Google Photos use this method. The system clusters similar faces together (unsupervised), so you only need to assign each person a single label. Semi-supervised learning methods combine the pattern-finding power of unsupervised methods with the precision of labeled examples.