Isolation
Isolation
What are database isolation levels, and how are they implemented.


Hi Friends,
Welcome to the 70th issue of the Polymathic Engineer newsletter.
This week, we discuss database isolation levels. In case you are unfamiliar with the topic, isolation levels are the mechanisms databases use to execute transactions as if there are no other concurrently running transactions.
The outline will be as follows:
Transactions and race condition
Isolation levels
Concurrency protocols
Something to think about
Transactions and race conditions
In a relational database, a transaction is a group of operations for which the database guarantees a set of properties known as ACID.
Transactions are significant because they allow developers to focus on the logic of their application without considering many possible failure scenarios.
Isolation is the most critical property and guarantees that transactions do not interfere with each other.
The easiest way to achieve this would be to use a global lock and run the transactions one after another. However, that would also be highly inefficient, so all databases allow transactions to run concurrently.
Two concurrent transactions, T1 and T2, can run into different kinds of race conditions:
1. dirty write: T1 overwrites a value written by T2 before T2 commits
2. dirty read: T1 sees a value written by T2 before T2 commits
3. fuzzy read: T1 reads different values for an object because T2 updated it between the reads
4. phantom read: T1 reads a set of objects matching a condition, but T2 adds, updates, or deletes those objects
Isolation levels
Databases offer isolation levels to protect against such race conditions, but they come with a trade-off. More robust levels protect against race conditions better but degrade performances.
There are four possible isolation levels, from weakest to strongest:
Read Uncommitted: Other transactions can read the data modification before committing a transaction.
Read Committed: Data modification can only be read after the transaction is committed.
Repeatable Read: Data read during the transaction stays the same as the transaction starts.
Serializable: Concurrent transactions are guaranteed to be executed in sequence.

Serialization is the only isolation level that protects against any race condition. It ensures that concurrent transactions have the same side effects as if they run serially in some order.
There is also a strict serialization level that guarantees the completion order of the transactions. However, that requires some coordination between transactions and is very slow.
Not all applications require the same guarantees, and databases allow you to set the isolation level. For example, I learned from reading PostgreSQL's docs that the default is "read committed."
Multi-Version Concurrent Control
The most widely used method for implementing isolation levels is Multi-Version Concurrent Control (MVCC), which treats read-only and write transactions differently.
When a transaction writes an object, the database creates a new version. A read transaction can access the latest object's version existing when it started.
This way, read transactions can be executed using a consistent snapshot of the data without aborting or blocking it because they conflict with a written transaction.
This is how the MySQL database implements MVCC. Each row has two hidden attributes: the transaction ID and the roll pointer.
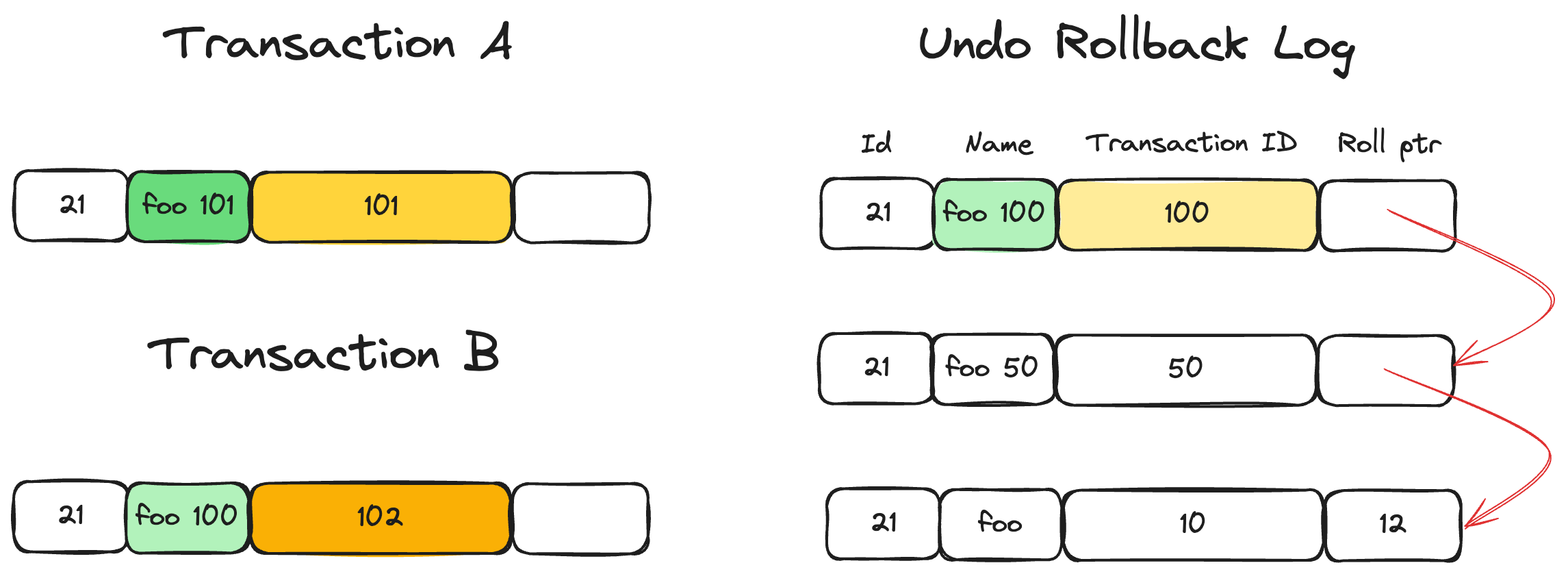
A new version with ID=101 is created when transaction A starts, and the roll pointer points to the old row. Afterward, when transaction B starts, another version with ID=102 is created.
Transaction B finds that the transaction with ID=101 is not committed and reads the previously committed record (ID=100). Even when transaction A commits, transaction B still reads data from the record with ID=100.
Concurrency control protocols
Write transactions are handled according to a concurrency control protocol. There are two categories of protocols that can guarantee serializability: pessimistic and optimistic.
Pessimistic protocols like two-phase locking (P2L) use locks to block transactions from accessing an object. They are effective in conflict-heavy scenarios since they avoid wasting time aborting and retrying transactions. However, two or more transactions can deadlock and get stuck.
Optimistic protocols like Optimistic Concurrency Control (OCC) allow transactions to execute without any block. They execute a write transaction in a local workspace, which is compared against the other workspaces before the commit. If a conflict is detected, the transaction is aborted and restarted.
Optimistic protocols are better in read-heavy scenarios since they avoid the load of handling locks and solving potential deadlocks.
Something to think about
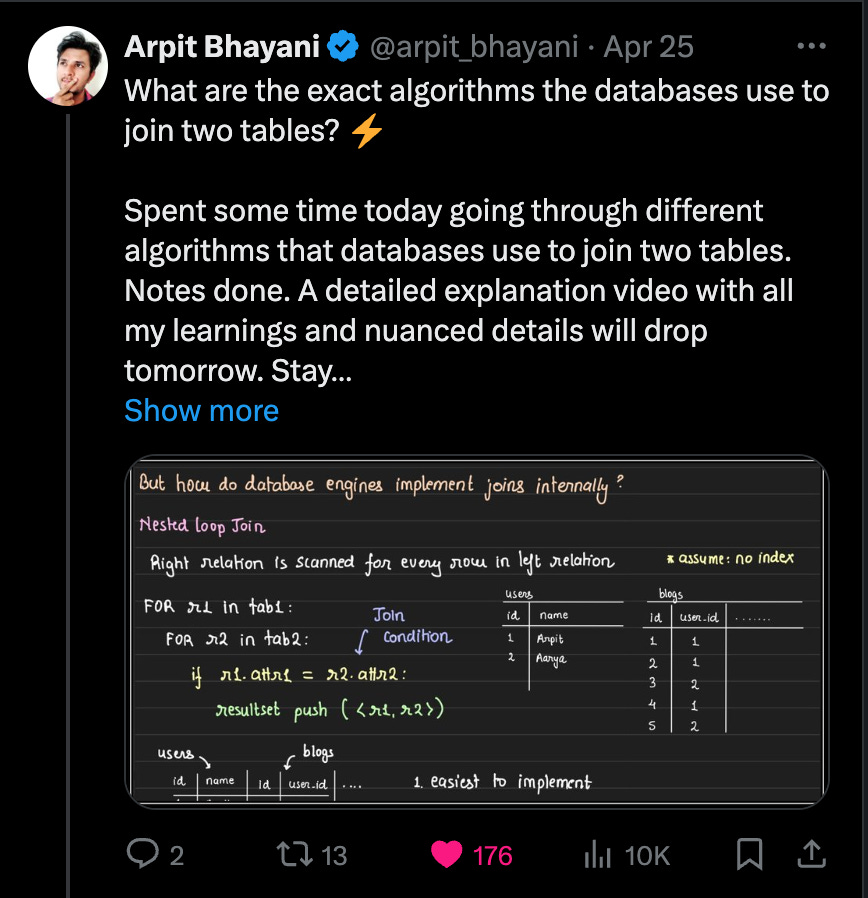
We often think that algorithms should be complicated. But it's interesting to see how databases combine rows with a simple nested loop algorithm. In its basic version, join has O(n^2) time complexity. Link
I understand using AI to filter out resumes when choosing candidates to interview. But if you don't even want an interviewer to show up to assess the candidates and you want AI to do it, that says a lot about your company.
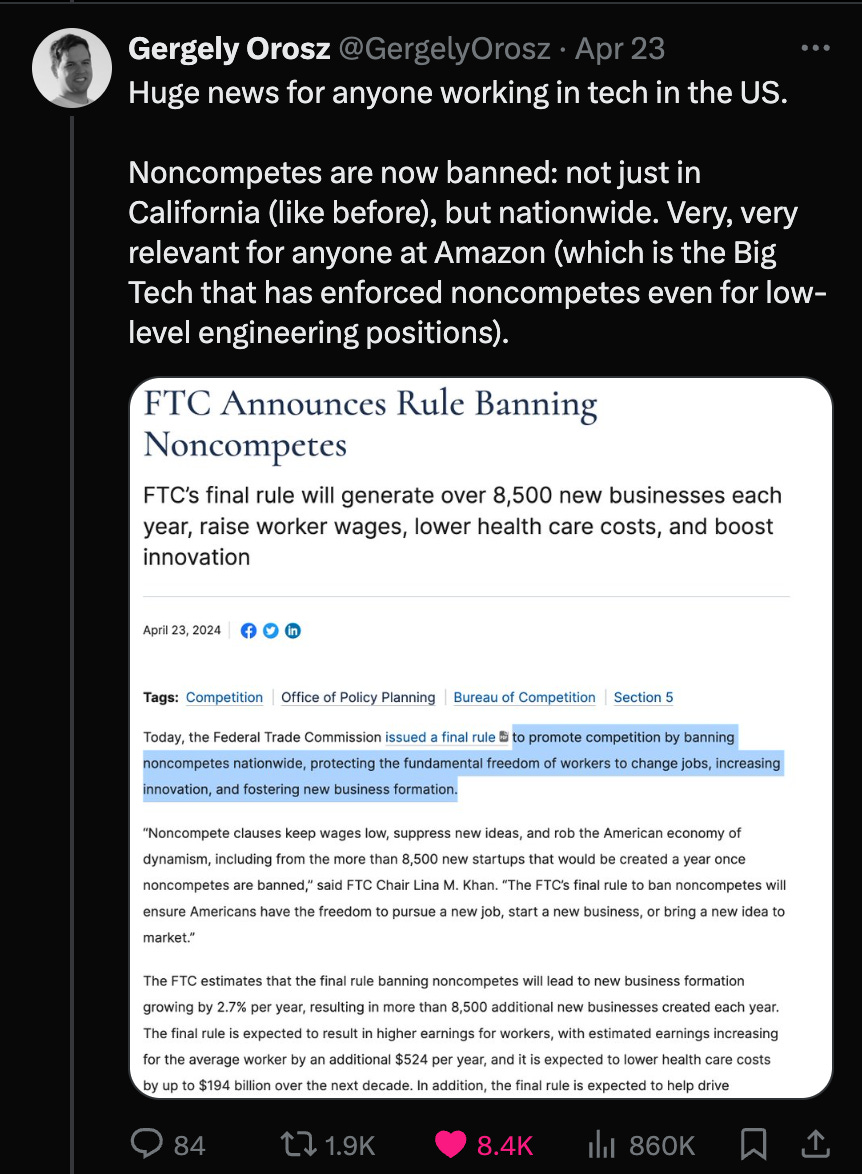
That's a significant and positive change for software engineers. The noncompete clause restricts people from freely changing jobs, decreases wages, and hinders fair competition.
Good referrals always beat the best job applications. Connecting with people is always a good use of time.